WAT (WebAssembly Text Format) と Common Lisp で遊ぶ ~小ネタ: 文字列出力マクロ~
相変わらずCommon Lisp + WAT (WebAssembly Text Format)で遊んでいますが、文字列の出力もできないと遊ぶには不便な感じがしたので、公式で紹介されている方法を参照しつつ、前々回の記事で作ったマクロつきパーサも活用しつつ、前回の記事で作ったメモリアロケータも利用しつつ文字列出力を簡易に行っていく記事です。
前々回記事: eshamster.hatenablog.com
前回記事: eshamster.hatenablog.com
目次
公式で紹介されている方法
まず公式のドキュメントである Understanding WebAssembly text format -WebAssembly Memory-で紹介されている方法に触れます(この項のコードは同ページから引用しています)。
まず、WASM側にimportさせる consoleLogString をJavaScript側で定義します。これは、WASMとの共有メモリ(memory)上の offset~offset+length-1 間をUTF8エンコードされたバイト列と解釈してデコードし、結果を console.log で出力するという代物です。
var memory = new WebAssembly.Memory({initial:1}); function consoleLogString(offset, length) { var bytes = new Uint8Array(memory.buffer, offset, length); var string = new TextDecoder('utf8').decode(bytes); console.log(string); }
この memory, consoleLogString は次のようにしてWASM側に渡します。
var importObject = { console: { log: consoleLogString }, js: { mem: memory } }; WebAssembly.instantiateStreaming(fetch('logger2.wasm'), importObject) .then(obj => { obj.instance.exports.writeHi(); });
WASM側は次のようになります。data セグメントを利用して、文字列 "Hi" をUTF8エンコーディングしたバイト列を memory 上に配置します。
(module ;; consoleLogString を $log として improt (import "console" "log" (func $log (param i32 i32))) (import "js" "mem" (memory 1)) ;; "Hi" をUTF8エンコーディングして memory 上に配置する (data (i32.const 0) "Hi") (func (export "writeHi") i32.const 0 ;; pass offset 0 to log i32.const 2 ;; pass length 2 to log call $log))
ということで、consoleLoeString が memory 上のバイト列を0~1(バイト単位)まで読み取ってUTF8デコードし、"Hi" を出力することになります。
func 中で同じことをしたい
C言語などでは固定文字列には固定のアドレスが割り付けられるようなので、ちゃんとしたコンパイラをつくる場合は前記の data セグメントをうまく使ってそうしたやり方を模倣するのが良いでしょう。が、もう少しカジュアルに遊びたいので、関数定義(func)中で固定文字列を出力する方法について(無駄に)考えてみます。
JavaScript側は前項から特に変更はありませんが、WAT側は data セグメントが func 中では利用できないので、別の方法を考える必要があります。
別の方法といっても、地道に自分でUTF8エンコードした文字列を memory 中に埋めていくしか(たぶん)ありません。そのため、"Hi"を出力するには次のようになります(関数呼び出し等はS式形式で書いています)。
(func test-log-string (i32.store8 (i32.const 0) (i32.const 72)) ; 72 = "H" (i32.store8 (i32.const 0) (i32.const 105)) ; 105 = "i" (call $log (i32.const 0) (i32.const 2)))
Asciiコードの範囲内ならまだマシで、「斑鳩」などと出力しようとすると次のようになります。
(func test-log-string ;; "斑" = (230 150 145) (i32.store8 (i32.const 0) (i32.const 230)) (i32.store8 (i32.const 1) (i32.const 150)) (i32.store8 (i32.const 2) (i32.const 145)) ;; "鳩" = (233 179 169) (i32.store8 (i32.const 3) (i32.const 233)) (i32.store8 (i32.const 4) (i32.const 179)) (i32.store8 (i32.const 5) (i32.const 169)) (call $log (i32.const 0) (i32.const 6)))
全然カジュアルじゃないですね。
マクロで簡単に書けるようにする
前々回の記事ではCommon LispにWATを書かせることができるようになりました。ここで一番やりたかったのがマクロの導入ですが、それを利用してもっと簡単に固定文字列の出力を書けるようにしてみます。なお、このWAT生成部分は watson というライブラリに切り出してみました。
先に、前項の test-log-string (と合わせてimport, export部分も)をこのwatsonを使って書く場合は次のようになります。
(defimport.wat log console.log (func ((i32) (i32)))) (defimport.wat mem js.mem (memory 1)) (defun.wat test-log-string () () ;; "斑" = (230 150 145) (i32.store8 (i32.const 0) (i32.const 230)) (i32.store8 (i32.const 1) (i32.const 150)) (i32.store8 (i32.const 2) (i32.const 145)) ;; "鳩" = (233 179 169) (i32.store8 (i32.const 3) (i32.const 233)) (i32.store8 (i32.const 4) (i32.const 179)) (i32.store8 (i32.const 5) (i32.const 169)) (log (i32.const 0) (i32.const 6))) (defexport.wat test-log-string (func test-log-string))
さて、これを次のように書けるように log-string マクロを作成します。なお、前回の記事でメモリアロケータ(malloc, free)を作ったので、それを使ってきちんとメモリを確保・解放する仕込みとして変数 ptr を用意しています*1。
(defun.wat test-log-string () () (let ((ptr i32)) (log-string "斑鳩" ptr)))
この log-string マクロの定義は次のようになります。
(defmacro.wat log-string (text var-ptr) (unless (stringp text) (error "input should be string. got: ~A" text)) (let* ((octets (flexi-streams:string-to-octets text :external-format :utf-8)) ;; octets は8バイト単位、malloc は32バイト単位であることに注意 (alloc-size (ceiling (/ (length octets) 4)))) `(progn (set-local ,var-ptr (malloc (i32.const ,alloc-size))) ,@(loop :for i :from 0 :below (length octets) :collect `(i32.store8 (i32.add (i32.mul ,var-ptr (i32.const 4)) (i32.const ,i)) (i32.const ,(aref octets i)))) (log (i32.mul ,var-ptr (i32.const 4)) (i32.const ,(length octets))) (free ,var-ptr))))
リストを出力するまではCommon Lispの領域なので、当然Common Lispライブラリも利用できます。ここでは、flexi-streamsを利用してUTF8エンコードしたバイト列 octets を生成しています。これを元に malloc で確保するサイズ alloc-size を計算しておきます。これらの情報を利用して、(progn 以下で下記を展開します。
alloc-size分のメモリをmallocする(32bit単位)- 確保したアドレスの先頭からバイト列の値を詰めていく(8bit単位)
logに格納したバイト列を指すようにoffset, lengthを渡す(8bit単位)freeで確保したメモリを解放する
ということで、次のように書けるようになります。先程は省略しましたが、自作 malloc, free を使う準備として init-memory も呼んでおきます。
(defun.wat test-log-string () () (let ((ptr i32)) (init-memory) (log-string "斑鳩" ptr)))
log-string マクロ部分を展開すると次のようになります。
(defun.wat test-log-string () () (let ((ptr i32)) (init-memory) (progn (set-local ptr (malloc (i32.const 2))) ;; "斑" = (230 150 145) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 0)) (i32.const 230)) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 1)) (i32.const 150)) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 2)) (i32.const 145)) ;; "鳩" = (233 179 169) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 3)) (i32.const 233)) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 4)) (i32.const 179)) (i32.store8 (i32.add (i32.mul ptr (i32.const 4)) (i32.const 5)) (i32.const 169)) (log (i32.mul ptr (i32.const 4)) (i32.const 6)) (free ptr))))
こんな風にマクロでわっと展開されると気分が良いですね。
*1:これが純粋にCommon Lispであればマクロ内で自分で変数を用意すれば良いのですが、WATでは関数冒頭でしか変数を用意できないのでそうもいかず...。ちょっとかっこ悪い。watsonパーサ側で中途に表れる変数宣言を関数冒頭に持ってくるなどすれば対処できそうですが、そこまではできておらず
WAT (WebAssembly Text Format) と Common Lisp で遊ぶ ~malloc, freeをつくる編~
lisp Advent Calendar 2020 22日目の記事です。
下記の続きになります。せっかくWATを書く(Common Lispに書かせる)準備ができたのでそれを使って何か書いてみます。
引き続き下記のリポジトリで遊んでいきます。
目次
作るもの
とりあえずWASM触ってみたいから始まっているので特に案もなかったのですが、メモリ管理機構もなさそうなので単純なメモリ確保(malloc), 解放(free)処理でも作ってみます。
リポジトリの src/wasm/sample.lisp からの抜粋になります。名前の通り、取りあえず動作確認のためのサンプルを突っ込んでいるファイルなので今回の内容と関係ないコードもあります。
概要
図を使って概要を説明します。初期状態も参考のために示していますが、2つ目の図の方を見ていきます。

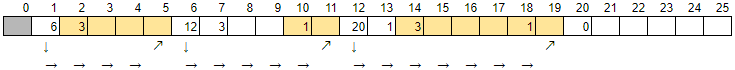
まず基本的な見方は次の通りです。
- 1つ1つの箱は32bitの領域を表す
- 以降これを「ブロック」と呼ぶ
- ブロックの中の数字は管理のために格納している数値を表す
- 空白になっている部分は任意の値が入る
- ブロックの外にある情報は説明のためのもの
- 上に乗っている数字は各ブロックのオフセットを表す
- ※下の矢印については後述
各ブロックの種類と内容は次の通りです。
- Null領域: 灰色のブロック
- オフセット0: ここは利用しない
- 確保済み領域: オレンジ色のブロック
- 各領域先頭のブロック内の数字はデータ領域(後続の空欄部分)のサイズを表す
- mallocした側には先頭の次のブロックのオフセットが返される
(これをポインタのように扱う)
- 例. 1番左の確保済み領域であればオフセット3をポインタとして扱う
- 未仕様領域
- 各領域先頭のブロックに入っている数字は次の空き領域のオフセットを表す
- ブロック下の矢印はこのつながりを表す
- 次のブロックに入っている数字は空き領域のサイズを表す
- 最初と最後の空き領域は特別な扱いをする
- 最初の空き領域は1つのブロックに次の空き領域へのオフセットだけを持つ
- 最後の空き領域は先頭のブロックに0を格納する
- 各領域先頭のブロックに入っている数字は次の空き領域のオフセットを表す
ここから想像されるように、malloc, free の大まかな動作は次のようになります(場合分け部分はちゃんと図で説明しないと伝わらないやつだなーと思いつつサボっているので雰囲気だけ...)。
malloc- 空き領域のオフセットを辿りながら必要サイズ以上の空きがある領域を見つけるか、
もしくは末尾の空き領域まで辿り着く
- この手前の空き領域をA, 見つけた空き領域をB, (あれば)次の空き領域をCとする
- 空き領域Bの先頭のブロックに容量の情報を入れる
- 元々入っていたCのオフセットは変数に退避しておく
- 状況に応じて空き領域を指すオフセットを調整する
- Bが末尾の空き領域である場合 → Aが指す先をBの次のブロックのオフセットにする
- そうでない場合
- Bが全て埋まった場合 → Aが指す先をCのオフセットにする
- Bがまだ残っている場合 → Aが指す先を残った領域の先頭のブロックのオフセットにし、 残った空き領域が指す先をCのオフセットにする
- 空き領域のオフセットを辿りながら必要サイズ以上の空きがある領域を見つけるか、
もしくは末尾の空き領域まで辿り着く
free- 解放する領域の手前の空き領域Aと後ろの空き領域Cを見つける
- 新たに解放する領域を空き領域Bとし、次のようにオフセットを調整する
- Aが指す先をBの先頭のブロックのオフセットにする
- Bが指す先をCの先頭のブロックのオフセットにする
- またBの2番目のブロックにサイズの情報を入れる
- 空き領域AまたはCと隣接している場合は空き領域をマージする
- Aとのみ隣接している場合
- Aが指す先をCの先頭のブロックのオフセットにする
- Aのサイズ情報にBのサイズを足す
- Cとのみ隣接している場合
- Cが末尾の空き領域である場合はBの先頭のブロックに0をセットする
- そうでない場合はBの指す先をCの次の空き領域のオフセットにする
- A, C両方と隣接している場合
- Cが末尾の空き領域である場合はAの先頭のブロックに0をセットする
- そうでない場合はAの指す先をCの次の空き領域のオフセットにする
- Aとのみ隣接している場合
(先頭と末尾を例外として)空き領域には次の2ブロック分の情報が必要な点に注意が必要です。
- 次の空き領域の先頭のオフセット
- 空き領域のサイズ
とすると、1ブロックだけ余ってしまうと空き領域として繋ぎ込むことができず、空いているのに永遠に利用できない領域になってしまいます。そこで、必ずメモリは2の倍数のサイズ(サイズ情報を入れるブロックを含めて)で確保するという力技で解決します。そのため、要求したサイズと実際に確保されたサイズが異なる場合があります。本来それらの情報は分けて持つべきですが、今回はそれをサボっているので、malloc で要求したサイズに対して大きめのメモリが割り当てられたことが呼び出し側から見えてしまったりします。まあそこは面倒なので妥協ということで...。
中身
前項が概要と言いつつ一通りのアルゴリズムを説明しているので、あとは地道にそれを実装していくだけです。
準備:メモリの用意
今回1次元の配列をメモリとして扱いますが、その1次元配列の用意です。
JavaScript側では次のように WebAssembly.Memory でメモリを用意してWASMに渡します。
const memory = new WebAssembly.Memory({initial:1}); var importObject = { console: { log: console.log }, js: { mem: memory } }; WebAssembly.instantiateStreaming(fetch('wasm/main.wasm'), importObject) .then(results => { results.instance.exports.test_list(); });
WASM側ではこれを次のようにimportします。
(defimport.wat mem js.mem (memory 1))
用語
メモリのオフセットはいくつかの意味で利用するので、変数の命名等で下記を使い分けています。
head:空き領域の先頭ブロックのオフセットptr(ポインタ):確保領域のヘッダ領域(*)を除いた先頭のブロックのオフセットmallocの返り値はこのオフセットになる
(*) 確保領域のサイズ情報を持つブロックのことで header と呼びます
補助関数
malloc, free の前にそれぞれで利用する補助関数を作っておきます。
i32 型の値のメモリからの読み取り・メモリへの格納には次の組み込み演算子が使えます。
;; メモリからの値の読み取り (i32.load <オフセット>) ;; メモリへの値の格納 (i32.store <オフセット> <格納する値>)
ただし、ここで言う「オフセット」には注意が必要で、これは32bitではなく8bitの単位になっています。今回、概要の項で説明したようにメモリ上のデータは32bit単位で扱います。毎回4をかけるのも面倒なので、32bit単位で扱えるload, store関数をそれぞれ用意しておきます。なお、以降オフセットといった場合は32bit単位のものを指します(プログラム中の "offset" も同様に32bit単位)。
(defun.wat load-i32 ((offset i32)) (i32) (i32.load (i32.mul offset (i32.const 4)))) (defun.wat store-i32 ((offset i32) (value i32)) () (i32.store (i32.mul offset (i32.const 4)) value))
次に、定数を表に出さないための関数群を定義していきます。それぞれソース中にコメントしていきます。
;; メモリ配列先頭のブロックはいわゆるNullポインタとして扱います (defun.wat get-null-ptr () (i32) (i32.const 0)) ;; 2番目(オフセット1)に最初の空き領域へのオフセットが入ります (defun.wat get-global-memory-head () (i32) (i32.const 1)) (defun.wat global-memory-head-p ((head i32)) (i32) (i32.eq head (i32.const 1))) ;; 末尾の空き領域の先頭には0が入ります (defun.wat last-empty-head-p ((head i32)) (i32) (i32.eqz (load-i32 head))) ;; 割り当てられたメモリ領域のヘッダサイズは1で、サイズ情報が入ります ;; (get-allocated-memory-header-size とかの方が良いかも...) (defun.wat get-header-size () (i32) (i32.const 1)) ;; 空き領域の先頭の次の領域には、空き領域のサイズ情報が入ります (defun.wat get-empty-memory-size ((head i32)) (i32) (load-i32 (i32+ head 1))) (defun.wat set-empty-memory-size ((head i32) (size i32)) () (store-i32 (i32+ head 1) size)) ;; 空き領域の先頭には次の空き領域のオフセットが入ります (defun.wat get-next-head ((head i32)) (i32) (load-i32 head)) ;; 「ポインタ」として呼び出し側に渡されるのはヘッダ以降の部分なので、 ;; そこから1つ手前に割り当てサイズの情報が入ります (defun.wat get-pointer-size ((ptr i32)) (i32) (load-i32 (i32- ptr 1)))
補助関数と分類して良いか微妙ですが、初期化用の関数も示します。
(defun.wat init-memory () () ;; オフセット1のブロックから、オフセット2の空き領域を指す (store-i32 (get-global-memory-head) (i32.const 2)) ;; オフセット2の空き領域は末尾の空き領域 (store-i32 (i32.const 2) (i32.const 0)))
malloc
malloc の実装は本体の他、2つの補助関数 adjust-malloc-size, malloc-recからなります。
malloc- シグネチャ
- 引数:
size= 確保したいメモリサイズ - 返り値:確保したメモリへのポインタ
- 引数:
- 実装的には
adjust-malloc-sizeでサイズを調整後、malloc-recを呼び出してその値を返すだけ
- シグネチャ
adjust-malloc-size- 概要で書いたように、半端なメモリを生まないためのサイズ調整をするのがここです
- シグネチャ
- 引数:
size= 確保したいメモリサイズheader-size= ヘッダのサイズalign-size= ※返り値の中で説明
- 返り値:
align-sizeの倍数かつsize+header-size以上の最小の値からheader-sizeを引いた値
- 引数:
malloc-rec- 概要で書いたような、空き領域を辿って十分な空きがある領域を探したり、 確保後に場合分けに応じてオフセットの値を書き換えたり... という一連の面倒な処理を引き受けている関数です
- シグネチャ
- 引数
size= 確保したいメモリサイズprev-head= 1つ手前の空き領域の先頭オフセットhead= 空き領域の先頭オフセット
- 返り値:確保したメモリへのポインタ
- 引数
それぞれ見ていきます。malloc の実装は上に書いた通り補助関数を呼ぶ程度のものです。
(defun.wat malloc ((size i32)) (i32) (let (((actual-size i32) (adjust-malloc-size size (get-header-size) (i32.const 2))) ((global-head i32) (get-global-memory-head))) (malloc-rec actual-size global-head (get-next-head global-head))))
次にメモリサイズを調整する adjust-malloc-size です。前述の「align-size の倍数かつ size + header-size 以上の最小の値から header-size を引いた値」を返すようにぼちぼち計算します。
(defun.wat adjust-malloc-size ((size i32) (header-size i32) (align-size i32)) (i32) (let* (((required i32) (i32+ size header-size)) ((rem i32) (i32.rem-u required align-size)) (aligned i32)) (if (i32.eqz rem) (set-local aligned required) ;; 境界まで足りない分を足す (set-local aligned (i32+ required (i32- align-size rem)))) (i32- aligned header-size)))
実装的には本丸の malloc-rec です。適宜コメントを補うので雰囲気を感じてください。ちなみに、前回実装した cond マクロのおかげで分岐の見通しが良いですね。
(defun.wat malloc-rec ((size i32) (prev-head i32) (head i32)) (i32) (let (((next-head i32) (get-next-head head)) (new-head i32) (rest-size i32) (result i32)) (cond ;; --- 末尾の空き領域の場合 --- ((i32.eq next-head (i32.const 0)) ;; ※全体のメモリが不足していたら伸ばす処理が必要ですがTODOのままです... ;; - 空き領域のオフセット調整 - ;; (set-local new-head (i32+ head size (get-header-size))) (store-i32 new-head (i32.const 0)) (store-i32 prev-head new-head) ;; - 確保した領域のポインタ返却準備 - ;; (store-i32 head size) (set-local result (i32+ head (get-header-size)))) ;; --- (末尾までに)十分な空きを見つけた場合 --- ((i32.ge-u (get-empty-memory-size head) size) ;; - 空き領域のオフセット調整 - ;; ;; 確保した後に空きが残っているか否かで場合分け (set-local rest-size (i32- (get-empty-memory-size head) size)) (if (i32.eqz rest-size) (set-local new-head next-head) (progn (set-local new-head (i32+ head size (get-header-size))) (store-i32 new-head next-head) ;; アラインメント調整で先頭の次のブロックが空いていることが保証されているので、 ;; そこに空き領域のサイズ情報をセットします (set-empty-memory-size new-head (i32- rest-size (get-header-size))))) (store-i32 prev-head new-head) ;; - 確保した領域のポインタ返却準備 - ;; (store-i32 head size) (set-local result (i32+ head (get-header-size)))) ;; --- 空きが不十分だった場合 --- ;; 次の空き領域を再帰的に見にいく (t (malloc-rec size head next-head) (set-local result)))) (get-local result))
free
free は補助関数を含め次のような関数からなります。
free- シグネチャ
- 引数:
ptr= 解放したいポインタ
- 引数:
- 補足:二重解放はご法度です(未定義動作)
- シグネチャ
find-prev-empty-head- 渡されたポインタの1つ手前の空き領域を見つける
- シグネチャ
- 引数:
ptr= ポインタ - 返り値:
ptrの1つ手前の空き領域の先頭のオフセット
- 引数:
- 補足:補助関数として
find-prev-empty-head-recを持つ
merge-empty-memory-if-enable- 2つの空き領域がマージ可能だったらマージする
- シグネチャ
- 引数
prev-head=headの1つ前の空き領域の先頭のオフセットhead= 空き領域の先頭のオフセット
- 返り値:マージ可能なら1, そうでなければ0
- 引数
コメントを補いながら実装を並べていきます。
まず free の実装です。補助関数を2つ呼ぶだけの malloc に比べると仕事が多いです。
(defun.wat free ((ptr i32)) () ;; ポインタの前後の空き領域を探す (let* (((prev-head i32) (find-prev-empty-head ptr)) ((next-head i32) (get-next-head prev-head)) ((new-head i32) (i32- ptr (get-header-size))) ((size i32) (get-pointer-size ptr))) ;; ポインタ領域を空き領域にする (store-i32 prev-head new-head) (store-i32 new-head next-head) (set-empty-memory-size new-head size) ;; 可能なら手前の空き領域にマージする (when (merge-empty-memory-if-enable prev-head new-head) ;; NOTE: ここで new-head を移動しておくことで↓で場合分けがいらなくなる (set-local new-head prev-head)) ;; 可能なら直後の空き領域にマージする ;; NOTE: そのまま呼ぶとi32型の値を返すことになってしまうのでwhenで囲っておく ;; もっと標準的なやり方がある気がする (when (merge-empty-memory-if-enable new-head next-head))))
次に、ポインタ手前の空き領域を探す find-prev-empty-head(-rec) です。
(defun.wat find-prev-empty-head-rec ((ptr i32) (head i32)) (i32) (let (((next-head i32) (get-next-head head)) (result i32)) (cond ((i32.eqz next-head) ;; 見つかる前に末尾の空き領域に着いてしまったケース(起こり得ない) (set-local result (i32.const 0))) ;; 見つかった ((i32.gt-u next-head ptr) (set-local result head)) ;; 見つからなかったので次を見る (t (find-prev-empty-head-rec ptr next-head) (set-local result))) (get-local result))) (defun.wat find-prev-empty-head ((ptr i32)) (i32) (find-prev-empty-head-rec ptr (get-global-memory-head)))
最後に、可能なら空き領域をマージする merge-empty-memory-if-enable です。
(defun.wat merge-empty-memory-if-enable ((prev-head i32) (head i32)) (i32) (let (((result i32) (i32.const 0))) ;; 最初の空き領域(オフセット1)にはマージしない (unless (global-memory-head-p prev-head) ;; 空き領域が隣接していることの確認 (when (i32.eq (i32+ prev-head (get-header-size) (get-empty-memory-size prev-head)) head) (store-i32 prev-head (get-next-head head)) ;; 末尾の空き領域でなければ足し合わせたサイズの値を格納する (unless (last-empty-head-p head) (set-empty-memory-size prev-head (i32+ (get-empty-memory-size prev-head) (get-header-size) (get-empty-memory-size head)))) (set-local result (i32.const 1)))) (get-local result)))
malloc, free を使ってみる: リスト構造
せっかく malloc, free を作ったので、これを使って下記のように cons 関数を作ってリスト構造を構成できるようにしてみます。
(defun.wat test-list () () (let ((lst i32)) (set-local lst (cons (new-i32 (i32.const 10)) (cons (new-i32 (i32.const 20)) (new-i32 (i32.const 30))))) (log (get-i32 (car lst))) ; -> 10 (log (get-i32 (car (cdr lst)))) ; -> 20 (log (get-i32 (cdr (cdr lst)))) ; -> 30 (free-typed lst)))
メモリ上のデータがコンスセルなのか数値(i32)なのかといったことを区別するため、ここで型を(雑に)導入します。型情報を持つデータはメモリ上で次のように表現されます。
- 1ブロック目:型を表すi32型の値が入る(以降「型ID」と呼ぶ)
- 2ブロック目以降:データ領域。このサイズや使い方はそれぞれの型によって決まる
ということで、型を定義する deftype.wat と補助関数を定義します。
;; ヘッダ = 型IDが入る領域 (defun.wat get-type-header-size () (i32) (i32.const 1)) ;; 確保領域の先頭のブロックには型を表す値が入る (defun.wat get-type ((ptr i32)) (i32) (load-i32 ptr)) ;; データは確保領域の2ブロック目から始まる (defun.wat get-type-data-offset ((ptr i32)) (i32) (i32+ ptr (i32.const 1))) ;; ※本文で解説 (defmacro deftype.wat (name size id) `(progn (defun.wat ,(symbolicate "MAKE-" name) () (i32) (let (((ptr i32) (malloc (i32+ (get-type-header-size) (i32.const ,size))))) (store-i32 ptr (i32.const ,id)) (get-local ptr))) (defun.wat ,(symbolicate name "-ID-P") ((typ i32)) (i32) (i32.eq typ (i32.const ,id))) (defun.wat ,(symbolicate name "-P") ((type-ptr i32)) (i32) (,(symbolicate name "-ID-P") (get-type type-ptr)))))
例えば、(deftype.wat hoge 2 1) とした場合、型ID = 1で hoge 型に関する3つの関数が生成されます(型IDは自動インクリメントなどにしたいところ...)。
make-hoge:mallocでhoge型に必要なメモリを確保してそのポインタを返すdeftype.watで指定したサイズ2 + ヘッダサイズ1 = 3ブロック分のメモリを確保する
hoge-id-p:渡された型IDがhoge型のものであるかを返すhoge-p:渡されたポインタ領域に入っているデータがhoge型であるかを返す
まずはこれを利用して、i32 型を型ID = 1で義します。データ領域にWATの i32 型の数値1つを持つだけの型です。取りあえず初期化関数, getter, setterとfree用の関数も用意します。
(deftype.wat i32 1 1) (defun.wat new-i32 ((value i32)) (i32) (let (((ptr i32) (make-i32))) (set-i32 ptr value) (get-local ptr))) (defun.wat get-i32 ((i32-ptr i32)) (i32) (load-i32 (get-type-data-offset i32-ptr))) (defun.wat set-i32 ((i32-ptr i32) (value i32)) () (store-i32 (get-type-data-offset i32-ptr) value)) (defun.wat free-i32 ((i32-ptr i32)) () (free i32-ptr))
次に肝心の cons-cell を型ID = 101で定義します。これはブロック2つ分のデータ領域を持ち、それぞれにポインタを格納します*1。
(deftype.wat cons-cell 2 101) (defun.wat cons ((ptr-car i32) (ptr-cdr i32)) (i32) (let (((ptr i32) (make-cons-cell))) (set-car ptr ptr-car) (set-cdr ptr ptr-cdr) (get-local ptr))) ;; データ領域の1ブロック目がcar部 (defun.wat car ((cons-cell-ptr i32)) (i32) (load-i32 (get-type-data-offset cons-cell-ptr))) (defun.wat set-car ((cons-cell-ptr i32) (value i32)) () (store-i32 (get-type-data-offset cons-cell-ptr) value)) ;; データ領域の2ブロック目がcdr部 (defun.wat cdr ((cons-cell-ptr i32)) (i32) (load-i32 (i32+ (get-type-data-offset cons-cell-ptr) (i32.const 1)))) (defun.wat set-cdr ((cons-cell-ptr i32) (value i32)) () (store-i32 (i32+ (get-type-data-offset cons-cell-ptr) (i32.const 1)) value)) ;; car部, cdr部のメモリも含めて解放する (defun.wat free-cons-cell ((cons-cell-ptr i32)) () (free-typed (car cons-cell-ptr)) (free-typed (cdr cons-cell-ptr)) (free cons-cell-ptr))
free-cons-cell は、任意の型のfreeを行う下記 free-typed との再帰定義になっています。
(defun.wat free-typed ((type-ptr i32)) () (cond ((i32-p type-ptr) (free-i32 type-ptr)) ((cons-cell-p type-ptr) (free-cons-cell type-ptr))))
ということで、冒頭に掲げた例のようにリストを構成できるようになりました(再掲)。
(defun.wat test-list () () (let ((lst i32)) (set-local lst (cons (new-i32 (i32.const 10)) (cons (new-i32 (i32.const 20)) (new-i32 (i32.const 30))))) (log (get-i32 (car lst))) ; -> 10 (log (get-i32 (car (cdr lst)))) ; -> 20 (log (get-i32 (cdr (cdr lst)))) ; -> 30 (free-typed lst)))
今後
とりあえずこんなのが考えられそう...ぐらいのもので特に具体的な展望はないやつです。
ガベージコレクタ...?
現状自分で malloc, free するしかないので参照カウンタ方式なりマーク・アンド・スイープ方式なりのガベージコレクタが欲しいところです。
純LISP...?
せっかくリスト構造ができたので純LISP(参考:Wikipedia, ポール・グレアム Lispの起源 (The Roots of Lisp))にも心惹かれるところです。今回 cons を作りましたが、この横に defun.wat で関数を並べてできる訳ではなく、cons で構成したリストをプログラムとして解釈するインタプリタをつくることが必要なのだろうなと思います。
おまけ:書き出されるWAT(抜粋)
前回作成したCommon Lispのガワを利用してWATを書いてきましたが、実際に書き出されるWATがどんなものかを見てみます。
まずは今回書いたもののうち、一番複雑な malloc-rec を再掲します。個人的にはがんばれば読めそうかな...という範疇に収まっているように見えます(そもそもが少々面倒なことをしているので、こうしてコメントを除くとちょっと辛い...というのは目をつむって見た目として)。
(defun.wat malloc-rec ((size i32) (prev-head i32) (head i32)) (i32) (let (((next-head i32) (get-next-head head)) (new-head i32) (rest-size i32) (result i32)) (cond ((i32.eq next-head (i32.const 0)) (set-local new-head (i32+ head size (get-header-size))) (store-i32 new-head (i32.const 0)) (store-i32 prev-head new-head) (store-i32 head size) (set-local result (i32+ head (get-header-size)))) ((i32.ge-u (get-empty-memory-size head) size) (set-local rest-size (i32- (get-empty-memory-size head) size)) (if (i32.eqz rest-size) (set-local new-head next-head) (progn (set-local new-head (i32+ head size (get-header-size))) (store-i32 new-head next-head) (set-empty-memory-size new-head (i32- rest-size (get-header-size))))) (store-i32 prev-head new-head) (store-i32 head size) (set-local result (i32+ head (get-header-size)))) (t (malloc-rec size head next-head) (set-local result)))) (get-local result))
そして、実際に書き出されるWATがこちらです(相変わらずインデントは手動)。こちらはがんば...る気がまず一目で削がれるのですがいかがでしょう?call や get_localなど、本質的にはプログラムには関係ない「装飾」が多過ぎるのかなと。WATそのものなのでシンタックスハイライトはきれいに出るのですが...。
※変数名や関数名は実際には大文字で書き出されますが、見た目の比較としてはアンフェアな気がしたので小文字に直しています(なお大文字の方がゴツくて読み辛い印象でした)
(func $malloc-rec (param $size i32) (param $prev-head i32) (param $head i32) (result i32) (local $next-head i32) (local $new-head i32) (local $rest-size i32) (local $result i32) (set_local $next-head (call $get-next-head (get_local $head))) (if (i32.eq (get_local $next-head) (i32.const 0)) (then (set_local $new-head (i32.add (get_local $head) (i32.add (get_local $size) (call $get-header-size)))) (call $store-i32 (get_local $new-head) (i32.const 0)) (call $store-i32 (get_local $prev-head) (get_local $new-head)) (call $store-i32 (get_local $head) (get_local $size)) (set_local $result (i32.add (get_local $head) (call $get-header-size)))) (else (if (i32.ge_u (call $get-empty-memory-size (get_local $head)) (get_local $size)) (then (set_local $rest-size (i32.sub (call $get-empty-memory-size (get_local $head)) (get_local $size))) (if (i32.eqz (get_local $rest-size)) (then (set_local $new-head (get_local $next-head))) (else (set_local $new-head (i32.add (get_local $head) (i32.add (get_local $size) (call $get-header-size)))) (call $store-i32 (get_local $new-head) (get_local $next-head)) (call $set-empty-memory-size (get_local $new-head) (i32.sub (get_local $rest-size) (call $get-header-size))))) (call $store-i32 (get_local $prev-head) (get_local $new-head)) (call $store-i32 (get_local $head) (get_local $size)) (set_local $result (i32.add (get_local $head) (call $get-header-size)))) (else (call $malloc-rec (get_local $size) (get_local $head) (get_local $next-head)) (set_local $result))))) (get_local $result))
次回
*1:もしかしたらポインタ型を用意してそれを持たせた方が良いのかもしれませんが、良し悪しをまだ検討できていません
WAT (WebAssembly Text Format) と Common Lisp で遊ぶ ~Common LispにWATを書かせる編~
lisp Advent Calendar 2020 15日目の記事です。
下記の続きになります。
引き続き下記のリポジトリで遊んでいきます。
WATを書くという意味ではまだ準備編で、薄めのラッパーをかけてCommon LispにWAT (WebAssembly Text Format) を書かせる話になります。下記が動機です。
- もう少しCommon Lispに寄せた構文で書きたい
- せっかくS式だから(原始的な)マクロを導入したい!
- なんか楽しそう
また、下記あたりを参考にしています。
追記:今回の部分は下記のライブラリに切り離してみました。
目次
- できたもの
- 中身
- 今後
- 次回
できたもの
例
今回の範囲はリポジトリのwa/ フォルダ以下にまとまっているものになります。それを使うと下記のような感じでWAT用の関数などが定義できます。とりあえず例として階乗関数 factorial を書いてみます。
若干型指定がうっとうしいですが、 defun.wat あたりはCommon Lisperからするとまあまあ見慣れた印象を受けるのではないでしょうか。
(defimport.wat log console.log (func ((i32)))) (defun.wat main () () (let (((x i32) (i32.const 5))) (log (factorial x)))) ;; Common Lispと異なり返り値を明示する必要があるので、 ;; 引数: ((x i32)) の横に返り値: (i32) が並んでいます(i32は型名) (defun.wat factorial ((x i32)) (i32) (let ((result i32)) (if (i32.ge-u (i32.const 1) x) (set-local result (i32.const 1)) (progn (i32.mul x (factorial (i32.sub x (i32.const 1)))) (set-local result))) (get-local result))) (defexport.wat exported-func (func main))
そして、これをロードしてから (princ (generate-wat-module)) すると下記のようにWATが吐き出されます(見易いように手でフォーマット*1)。
(module (import "console" "log" (func $LOG (param i32))) (func $MAIN (local $X i32) (set_local $X (i32.const 5)) (call $LOG (call $FACTORIAL (get_local $X)))) ; -> 120 (func $FACTORIAL (param $X i32) (result i32) (local $RESULT i32) (if (i32.ge_u (i32.const 1) (get_local $X)) (then (set_local $RESULT (i32.const 1))) (else (i32.mul (get_local $X) (call $FACTORIAL (i32.sub (get_local $X) (i32.const 1)))) (set_local $RESULT))) (get_local $RESULT)) (export "exported_func" (func $MAIN)))
パッと見で全体的にゴツくなった印象を受けるかと思いますが、defun.wat 周りに注目していくつか特徴を拾ってみます。
- 変数に自動で
$をつけてくれている- 例.
x→$X
- 例.
- 関数呼び出しでは関数名に
$をつけた上でcallも付与してくれている- 例.
(factorial ...)→(call $FACTORIAL ...) - これはimportした
log関数についても同様 - 一方、
i32.mulなど組み込みの演算子にはcallはついていない
- 例.
- 関数や組み込み演算子の引数に変数を指定した場合、自動で
get_localをつけてくれている- 例.
(factorial x)→(call $FACTORIAL (get_local $X)) - 個人的には
get_localが乱舞していると読む時に非常に疲れるので割と大事 - (型情報を使って頑張れば直値指定についている
i32.constも取れそうですがサボってます...)
- 例.
let(もどき)やifが良い感じに展開されている- これはマクロとして実現していたりします
マクロも書ける
上記の例で使っている if, let も地味にマクロとして定義しているのですが、同じ枠組みを使って自分で定義することもできます。
若干長いですが、まあまあ複雑なものも書ける例として、任意個数の i32 型の引数をとってかけ算ができる i32* マクロを書いてみます。WATで i32 型のかけ算に使う i32.mul 演算子は引数が2つで固定なので、これをネストしていく感じになります。マクロ処理は単にCommon Lisp内でのリスト処理なので、普通のマクロと同じ感覚で書けます。 gensym すらない原始的な代物ではありますが...
(defimport.wat log console.log (func ((i32)))) (defmacro.wat i32* (&rest numbers) (flet ((parse-number (number) (cond ((numberp number) `(i32.const ,number)) ((atom number) `(get-local ,number)) (t number)))) (case (length numbers) ;; 引数が0個の場合は固定で1を返すようにする (0 `(i32.const 1)) (t (labels ((rec (rest-numbers) (let ((head (car rest-numbers)) (rest (cdr rest-numbers))) (if rest ;; i32.mul をネストする `(i32.mul ,(parse-number head) ,(rec rest)) (parse-number head))))) (rec numbers)))))) (defun.wat main () () (let (((x i32) (i32.const 4))) (log (i32*)) ; -> 1 (log (i32* 1 2 3)) ; -> 6 (log (i32* 1 2 3 x)))) ; -> 24 (defexport.wat exported-func (func main))
先程の例と同じく (princ (generate-wat-module)) すると下記のようなWATが吐き出されます(相変わらず手でフォーマット)。マクロ定義は展開時にのみ使う情報なのでWAT側には出てきません。main部分はマクロが展開されてだいぶ長くなりました。
(module (import "console" "log" (func $LOG (param i32))) (func $MAIN (local $X i32) (set_local $X (i32.const 4)) (call $LOG (i32.const 1)) (call $LOG (i32.mul (i32.const 1) (i32.mul (i32.const 2) (i32.const 3)))) (call $LOG (i32.mul (i32.const 1) (i32.mul (i32.const 2) (i32.mul (i32.const 3) (get_local $X)))))) (export "exported_func" (func $MAIN)))
中身
全部は見ないですが、defun.wat 周りをかいつまんで中身の実装を見ていきます。再掲ですが、リポジトリのwa/ フォルダ以下の内容になります。説明を見ると分かりますが何かと雑な感じです...
基本的なアイディア
先程見た変換時の特徴を若干整理して再掲します。
- 変数に自動で
$をつけてくれている - 関数呼び出しでは関数名に
$をつけた上でcallも付与してくれている- 一方、
i32.mulなど組み込みの演算子にはcallはついていない
- 一方、
- マクロが展開される
- 関数や組み込み演算子の引数に変数を指定した場合、自動で
get_localをつけてくれている
最後の項目は割と展開時の小手先の話なので置いておくと、何らかの手段で展開時に変数や関数やマクロを識別していることが分かります。その識別のための情報を格納する仕組みさえできてしまえば、後は割と地道にパースしていくだけという感じになります。結論から言うとCommon Lispのシンボルシステムを(かなり雑に)参考にしています。
ということでCommon Lispの方を少し見てみます。(defun hoge...) で関数を定義すると何が起きるかというと hoge というシンボルの関数領域 = symbol-function に関数の実体が入ります。正確な言い方ではないですが、この辺りに入っている情報を見て (hoge) というリスト表現が hoge 関数の呼び出しであるという判断もつくようになります*2。
CL-USER> (defun hoge () 100) HOGE CL-USER> (hoge) 100 CL-USER> (symbol-function 'hoge) #<Compiled-function HOGE #x30200149C13F> ;; 返されているのは関数の実体なので funcall して呼ぶこともできる CL-USER> (funcall (symbol-function 'hoge)) 100 ;; 余談: symbol-function で symbol-function の実体も取り出せる CL-USER> (symbol-function 'symbol-function) #<Compiled-function SYMBOL-FUNCTION #x30000016720F> CL-USER> (funcall (symbol-function 'symbol-function) 'symbol-function) #<Compiled-function SYMBOL-FUNCTION #x30000016720F>
これを踏まえて、大まかな実装方針としては下記のようになります。
- ユーザ定義の関数定義を格納するシンボル様の構造体を用意する
- ※組み込み関数もこの仕組みに乗せられそうですが、現状サボって個別に並べています
- 上記構造体の集合を格納するテーブルをグローバルに用意する
- Common LispのEnvironmentに相当するもの...のつもり
defun.watやdefmacro.watで定義したものは上記のテーブルに格納していく
wat-symbol と wat-environment
wa/environment.lispに定義した wat-symbol, wat-environment について見ていきます。上で書いた大まかな実装方針との関係は次のようになります。
- ユーザ定義の関数定義を格納するシンボル様の構造体を用意する →
wat-symbol - 上記構造体の集合を格納するテーブルをグローバルに用意する →
wat-environment
wat-symbol
まず wat-symbol 構造体の定義は下記のようになっています。
(defstruct wat-symbol symbol import ; defimport.wat したものを入れる function ; defun.wat したものを入れる macro-function ; defmacro.wat したものを入れる var ; ローカルな変数を格納する )
symbol にはCommon Lispのシンボルを入れて識別子に利用します*3。
残りのフィールドはそのシンボルにひもづいているものが入ります。例えば、後で詳しく見る defun.wat をすると function フィールドに関数の定義がセットされます。セット時は下記のように defsetf を定義しているので、 (setf (wsymbol-function wsymbol) 値) のようにセットできます。定義を見て分かるように、現状は複数のフィールドに同時に値が入らない形になっています。
(defun set-function-empty (wsymbol) (when (wat-symbol-function wsymbol) (warn "~A has been defined as WAT function" (wat-symbol-symbol wsymbol))) (setf (wat-symbol-function wsymbol) nil)) ;; ~略~ 各フィールド用の set-XXX-empty 関数 (defun wsymbol-function (wsymbol) (wat-symbol-function wsymbol)) (defsetf wsymbol-function (wsymbol) (func) ;; 他のフィールドは全部クリアして function フィールドのみに値が入った状態にする `(progn (setf (wat-symbol-function ,wsymbol) ,func) (set-macro-function-empty ,wsymbol) (set-import-empty ,wsymbol) (set-var-empty ,wsymbol) ,wsymbol)) ;; ~略~ 各フィールド用の getter (defun), setter (defsetf)
ここまで書いておいて何ですが、 wat-symbol にどのようなフィールドを持たせるべきか、どのような値をセットするべきかというところは正直十分に練れていません。例えば、現状は関数をインポートしてもメモリをインポートしても import フィールドに突っ込まれますが、プログラム上の扱いが異なるので適切に割り振る方が良い気がしています。現状パーサがそれほど賢くないので問題になっていないですが、もっと賢いこと(関数のシグネチャを見て何かしたいとか)をしようとしたときに問題になりそうです。
wat-environment
次に wat-environment ですが、これは現状どんな束縛が存在するかを表す構造体で、実体としては wat-symbol の集合を持っているだけです。なお、検索速度の都合上シンボルをキー、wat-symbol を値としたハッシュテーブルを持たせていますが、シンボルの情報は wat-symbol 自体にも含まれるので単なる wat-symbol のリストでも動作上は問題ありません。
(defstruct wat-environment (symbol-to-wat-symbols (make-hash-table))) ;; グローバルなwat-environmentの用意 (defvar *global-wat-env* (make-wat-environment))
この wat-environment から wat-symbol を取り出したり生成したりする最も基本的な関数が次の intern.wat になります。名前の通りintern関数を真似ていて、*global-wat-env* 内に識別子(シンボル)に対応する wat-symbol があればそれを返し、なければ生成 & *global-wat-env* に登録して生成したものを返します。
(defun intern.wat (sym) (let ((table (wat-environment-symbol-to-wat-symbols *global-wat-env*))) (multiple-value-bind (wsym found) (gethash sym table) (when found (return-from intern.wat wsym)) (setf (gethash sym table) (make-wat-symbol :symbol sym)))))
先程見た wat-symbol に対する setf と合わせて見ると、例えば関数定義ですべきことは下記のような形になります。
(setf (wsymbol-function (intern.wat sym)) 値)
wat-environment の本質的な役目としては以上ぐらいで、あとは特定フィールドに値を持つ wat-symbol の(キーとなるシンボルの)一覧を取り出す wenv-xxx-symbols など補助的な関数が並びます(コードは略)。
defmacro.wat
定義系は関数定義の defun.wat とマクロ定義の defmacro.wat を見ていきますが、やっていることは意外とシンプルな後者のマクロの方から見ていきます。wa/defmacro.lisp が該当のファイルになります。
Lisp におけるマクロは結局のところ、引数を受け取って(式として評価可能な)リストを返すだけの関数に過ぎないので、プログラムがリストとして表されるS式の世界に導入するのは簡単です(なんの安全性もない原始的なものであればという話ですが)。マクロを定義する defmacro.wat とマクロを展開する macroexpand(-1).wat について見ていきます。
まずは defmacro.wat です。
(defmacro defmacro.wat (name lambda-list &body body) (with-gensyms (params env) `(progn (setf (wsymbol-macro-function (intern.wat ',name)) (lambda (,params ,env) ;; ※env = wat-environment は渡す方法・使う方法を何も考えていないので、 ;; 現状Common Lispのマクロに合わせて受け取れるようにだけはしている状態です (declare (ignorable ,env)) (destructuring-bind ,lambda-list (cdr ,params) ,@body))) ;; エディタ上でマクロ展開結果を簡単に見られるようにCommon Lispのマクロも定義しておく。 ;; CLパッケージのものを書き換えると怒られるので名前の後ろに "%" をつけて雑に避けています。 (defmacro ,(symbolicate name "%") ,lambda-list ,@body))))
wat-environment の項で見たように (setf (wsymbol-macro-function (intern.wat ',name)) 値) のイディオムを使って wat-symbol に関数を登録しています。登録している関数については下記の例で考えてみます。
(defmacro.wat hoge-macro (a b) `(i32.add (i32.const ,a) (i32.const ,b)
これを利用するときは (hoge-macro 1 2) のように書きますが、このリスト自体が第1引数の params として渡ります。リストの先頭は不要なので残りの (1 2) を (destructuring-bind (a b) '(1 2)) ...) して変数 a, b に束縛します。あとは body 部でこれを利用するだけです。env はCommon Lispではlexical environmentを渡すために利用しますが、特に考えてないので置いておきます。
次に定義に従ってマクロを展開する macroexpand(-1).wat です。上記の例で言えば (macroexpand.wat '(hoge-macro 1 2)) とすると (i32.add (i32.const 1) (i32.const 2)) を返す関数です。
最初に補助関数として、渡されたformがマクロとして展開可能か、可能であれば登録された展開関数を返す macro-function-if-expandable を作ります。これはformの先頭のシンボルを元に intern.wat して wat-symbol を取り出し、その macro-function フィールドに値があるかで判別ができます。
(defun macro-function-if-expandable (form env) (when (atom form) (return-from macro-function-if-expandable nil)) (let ((*global-wat-env* env)) (let ((wsym (intern.wat (car form)))) (wsymbol-macro-function wsym))))
この macro-function-if-expandable を呼んでマクロ展開関数が返ってきたらそれにformを渡して展開結果を返す、そうでなければそのままformを返す、とすれば macroexpand-1 のでき上がりです。 macroexpand は同じことを再帰的にやるだけです。これは後で見る body-parser の中でマクロを展開するのに利用します。
(defun macroexpand-1.wat (form &optional (env *global-wat-env*)) (let ((mf (macro-function-if-expandable form env))) (if mf (funcall mf form env) form))) (defun macroexpand.wat (form &optional (env *global-wat-env*)) (labels ((rec (form) (let ((mf (macro-function-if-expandable form env))) (if mf (rec (funcall mf form env)) form)))) (rec form)))
defun.wat
関数を定義する defun.wat を見ていきます。該当のファイルはwa/defun.watになります。
defun.wat マクロの定義は次の通りです。
(defmacro defun.wat (name args result &body body) `(progn (setf (wsymbol-function (intern.wat ',name)) (lambda () ;; generate-defun については後述 (generate-defun ',name ',args ',result ',body))) ;; 関数ジャンプしたりシグネチャをエディタに表示させたいので、 ;; 空のCommon Lisp関数を定義しておく(CLパッケージのシンボルを除く) ,(unless (eq (symbol-package name) (find-package "CL")) (defun-empty% name args))))
先程の defmacro.wat にもあった (setf (wsymbol-function (intern.wat sym)) 値) のイディオムが出てきます。ここで値として登録しているのは、呼び出すとWATとしてprint可能なリストを吐き出す関数です。リストそのものを登録しないのは、「マクロは純粋に関数的であるべき(引数以外に結果が左右されてはならない)」という原則を守るためです。というのは、defun.wat のbody部のパース処理はグローバルな *global-wat-env* に依存しているため、「純粋に関数的」ではないためです。実際的な問題としては、defun.wat の順序によってパース結果が変わってしまうという問題が起こります。
登録した関数の中で呼んでいる generate-defun は次の形になっています。
(defun generate-defun (name args result body) (multiple-value-bind (parsed-typeuse vars) (parse-typeuse (list args result)) `(|func| ,(parse-arg-name name) ,@parsed-typeuse ,@(parse-body body vars))))
parse-arg-name: 受け取ったシンボルに$プレフィックスをつけているだけです- 例.
hoge→$hoge - 名前がよろしくない...
- 例.
parse-typeuse: 引数と返り値のパースを行います- 例.
( ((a i32) (b i32)) (i32) )→((param a i32) (param b i32) (result i32))paramやresultを一々書くのがうっとうしいなと思ったので分けて書く形にしてみました
- 定義はwa/type.lispにあります
- "typeuse" という名称はWATの仕様から取っています
- 例.
parse-body: これは次節で詳しく見ますが、名前の通りbody部をパースします
短いものなので、ついでに空のCommon Lisp関数定義に利用している defun-empty% も載せておきます。
(defun defun-empty% (name args) ;; defun.wat の引数は ((a i32) (b i32)) の様に型情報がついているので、変数名だけ取り出す (let ((args-var (mapcar #'car args))) `(defun ,name ,args-var (declare (ignore ,@args-var)))))
body-parser
defun.wat で利用していた body-parser について見ていきます。ここまで来ればもう渡されたリストを地道にパースしていくだけです(と言えるのがS式の良い所ですね)。
ファイルはwa/body-parser.lispになります。
関数引数の束縛
parse-body の全体は下記のようになっています。
(defun parse-body (body args) (let ((*org-global-wat-env* *global-wat-env*) (*global-wat-env* (clone-wenvironment))) (dolist (arg args) (setf (wsymbol-var (intern.wat arg)) t)) (flatten-progn-all (parse-form body))))
ここではまず、関数引数の束縛、すなわちbody部分をパースする中で関数自体の引数をローカル変数として認識できるようにします。次の2ステップで実現します。
- グローバルな
wat-environmentを保管する*global-wat-env*に自身のクローンを束縛する *global-wat-env*に(setf (wsymbol-var (intern.wat arg)) t)で各引数シンボルに対応するwat-symbolのvarフィールドを設定する- ステップ1によりオリジナルの
wat-environmentには影響しない
- ステップ1によりオリジナルの
要するに、該当の関数内だけで通用するローカルな wat-environment を構成しています。Common Lispで似たものはlexical environmentになりそうですが、こちらはlexical environment → global environmentの順で束縛を探す仕様です。つまりは同一シンボル(名)の隠蔽ができます。一方こちらはグローバルな wat-environment のクローンにそのまま値を突っ込んでいるのでそうした隠蔽ができません*4。そもそもWAT上で変数名が衝突するとエラーになるはずなので、まあそのぐらいの雑な対応で良いかという感じです(もちろんパーサで頑張れば擬似的に回避できるはずですが...*5)。
parse-form: パース処理の入口
さて、parse-body の残りの部分の (flatten-progn-all (parse-form body)) ですが、flatten-progn-all は最後に見るとして、パースの本処理である parse-form の方を見ていきます。
(defun parse-form (form) (cond ((atom form) (parse-atom form)) ((special-form-p form) (parse-special-form form)) ((built-in-func-form-p form) (parse-built-in-func-form form)) ((macro-form-p form) (parse-macro-form form)) ((function-call-form-p form) (parse-function-call-form form)) (t (mapcar (lambda (unit) (parse-form unit)) form))))
見ての通り、この関数自体はパース処理を何もしておらず、formの種類に応じて適切なパース関数に投げるだけの人です。投げた先でも困ったら取りあえずこの parse-form に投げるというように窓口的な関数です。以下で各パース関数を順に見ていきます。
※解説しやすい形で順序は適当に前後します(例えば、スペシャルフォームは関数でもマクロでもないもの、という感じなので parse-special-form は後ろの方で見ます)
parse-atom: atom(=リストでないもの)のパース
atom(=リストでないもの)をパースする parse-atom は次のようになります。
(defun parse-atom (atom) (if (var-p atom) (parse-arg-name atom) atom)) (defun var-p (sym) (some (lambda (syms) (find sym syms)) (list (wenv-var-symbols) (wenv-function-symbols) (wenv-import-symbols))))
wat-symbol として登録されたシンボルであれば $ をプレフィックスにつける(例. hoge → $hoge)、そうでなければそのまま返すぐらいの仕事です。var-p がだいぶ大雑把なので (wenv-var-symbols) だけを見るようにしたいところですが、現状 parse-atom を雑に使っている影響があり、そこからのリファクタ案件です...。
parse-built-in-func-form: 組み込み関数のパース
組み込み関数をパースする parse-built-in-func-form は次のようになります。
(defun parse-built-in-func-form (form) `(,(convert-built-in-func (car form)) ,@(mapcar (lambda (elem) (parse-call-arg elem)) (cdr form)))) (defun parse-call-arg (arg) ;; ※これは後述の parse-func-call-form でも共通に使う (if (and (atom arg) (var-p arg)) (parse-form `(get-local ,arg)) (parse-form arg)))
parse-built-in-func-form について、まずはどのようなパースをしているのか例を見ます。
;; ※ "x" は関数の引数またはローカルな変数とする (parse-build-in-func-form '(i32.add x (i32.const 1))) -> (|i32.add| (|get_local| $x) (|i32.const| 1))
細かい部分の説明は省略しますが、
i32.addはconvert-built-in-funcによって|i32.add|になるx,(i32.const 1)はそれぞれparse-call-argでパースするxの場合はget-localをくっつけた(get-local x)をパースした結果、(|get_local| $x)になる(i32.const 1)はそのままパースした結果(|i32.const| 1)になる
といった感じになります。記事冒頭の例で示した「関数や組み込み演算子の引数に変数を指定した場合、自動で get_local をつけてくれている」はここでやっている訳です。
フォームの判別を行う built-in-func-form-p は次のような形で、wa/built-in-funcで定義している built-in-func-p を呼ぶだけです(組み込み関数は一通りハッシュテーブルに突っ込んでいるので、そこに入っているかを確認する程度の処理)。
(defun built-in-func-form-p (form) (built-in-func-p (car form)))
parse-function-call-form: 関数呼び出し処理のパース
関数呼び出し処理をパースする parse-function-call-form は次のようになります。
(defun parse-function-call-form (form) (destructuring-bind (func &rest args) form `(|call| ,(parse-atom func) ,@(mapcar (lambda (arg) (parse-call-arg arg)) args))))
大体前項の parse-built-in-func と似たような感じですが、こちらも例を見てみます。
;; ※ "hoge" は関数、"x" は関数の引数またはローカルな変数とする (parse-build-in-func-form '(hoge x (i32.const 1))) -> (|call| $hoge (|get_local| $x) (|i32.const| 1))
parse-built-in-func と異なる部分についてだけ見ると、
- 頭に
|call|がつけられる - 関数名に
$プレフィックスがつけられる
となります。こうした違いがあるためパース関数を分けています。一方で、引数の処理についてはどちらも共通しています。
フォームの判別を行う function-call-form-p は次のようになります。
(defun function-call-form-p (form) (let ((sym (car form))) (some (lambda (syms) (find sym syms)) (list (wenv-function-symbols) (wenv-import-symbols)))))
リスト先頭のシンボルに対応する wat-symbol の function または import フィールドに値が入っているかを調べています。前述のようにインポートしたものを区別せずに import に突っ込んでいる(関数のインポートの場合もある)ので、両方見る必要が出てきています...。 function フィールドの方を見るだけで良いようにリファクタリングすべき案件です。
parse-macro-form: マクロフォームのパース
マクロフォームをパースする parse-macro-form は次のようになります。
(defun parse-macro-form (form) (parse-form (macroexpand.wat form *org-global-wat-env*)))
先程見た macroexpand.wat を呼び出すだけです。第2引数としてはローカルな束縛が渡らないように、地味に parse-body で保存したグローバルな wat-environment を渡すようにしていますが、そもそも現状渡した env を利用していないので一応程度です。
フォームの判別を行う macro-form-p は次のようになります。リスト先頭のシンボルに対応する wat-symbol の macro-function フィールドに値が入っているかを調べるだけです。
(defun macro-form-p (form) (wsymbol-macro-function (intern.wat (car form))))
parse-special-form: スペシャルフォームのパース
スペシャルフォームをパースする specifal-form-p は長めなので抜粋して見ていきます。
(defun parse-special-form (form) (ecase (car form) (progn `(progn ,@(mapcar (lambda (unit) (parse-form unit)) (cdr form)))) (local (destructuring-bind (var type) (cdr form) (setf (wsymbol-var (intern.wat var)) t) `(|local| ,(parse-atom var) ,(convert-type type)))) ;; ~略~ (set-local (parse-1-arg-special-form '|set_local| (cdr form))) ;; ~略~ )) (defun parse-1-arg-special-form (head args) `(,head ,(parse-form (car args)) ,@(mapcar (lambda (unit) (parse-call-arg unit)) (cdr args))))
progn はCommon Lispのそれと似たようなもので、cdr 以降の要素をそれぞれ parse-form した上で progn で包み直します。progn は一通りパースが終わるまでは残したままにしますが、WATとしてはゴミなので後から flatten-progn-all で取り除きます。
local は (local x i32) のような形でローカル変数を定義するための構文です。(setf (wsymbol-var (intern.wat var)) t) のようにして、環境に変数を登録しているのが特徴です。このように環境をいじることは関数やマクロとしては実現できないので、スペシャルフォームとして実現する必要があります。
set-local は (set-local x y) のような形でローカル変数に値をセットする構文です。パース後の形は (|set_local| $X (|get_local| $Y)) のようになりますが、関数のパースと比べると第1引数を特別扱いしている = |get_local| をつけていません。こうした特別扱いも関数やマクロとしてはやはり実現できません。
フォームの判別を行う special-form-p は単に並べたスペシャルフォームを表すシンボルに一致するかを見るだけです。
(defun special-form-p (form) (case (car form) ((progn local block loop get-local set-local get-global set-global br br-if) t) (t nil)))
flatten-progn-all
最後に (flatten-progn-all (parse-body body)) としてパース結果に対して呼んでいた flatten-progn-all です。
(defun flatten-progn-all (body) (labels ((progn-p (target) (and (listp target) (eq (car target) 'progn))) (rec (rest) (cond ((atom rest) rest) (t (mapcan (lambda (unit) (if (progn-p unit) (rec (cdr unit)) (list (rec unit)))) rest))))) (rec body)))
これは、例えば ((progn 1 2) 3 ((progn 4 (progn 5)))) というリストが渡されたら (1 2 3 (4 5)) のように progn 部分をフラット化して返す関数です。これは主に、複数の式を並べて返すようなマクロを実現するために導入したものです。単純にリストに並べて返してもWATとしては余計なカッコが残ってしまうので、progn から始まるリストは親リストにくっつける目印に使うことにしました。
WATの書き出し
defun.wat の実装を振り返ると、単にWATとしてprint可能なリストを出力するための関数を登録していただけでした。ということで、実際にそれらをまとめて呼び出して出力する人が必要になります。
それがwa/module.lispの generate-wat-module です。
(defun generate-wat-module% () `(|module| ,@(mapcar #'funcall (wenv-import-body-generators)) ,@(mapcar #'funcall (wenv-function-body-generators)) ,@(mapcar #'funcall (get-export-body-generators)))) (defun generate-wat-module () (let ((str-list (clone-list-with-modification (generate-wat-module%) (lambda (elem) (typecase elem (symbol (symbol-name elem)) (string (format nil "~S" elem)) (t elem)))))) str-list))
解説は省略していましたが defimport.wat, defexport.wat も関数を登録しているので、合わせて generate-wat-module% で呼び出して、頭に |module| をくっつけて結合します。詳細略ですが、 generate-wat-module はそれを呼び出した後、princ 関数でうまくWATとして解釈可能な文字列が出力されるように細かい調整をしています。
ということで、(princ (generate-wat-module)) の結果をファイルに出力すれば、1つのmoduleを定義したWATファイルが手に入るようになりました。
いくつかのデフォルトマクロ
WATを吐き出すパーサとしては以上ですが、条件分岐系でいくつかデフォルトのマクロを提供しているのでザックリ見てみます。ファイルはwa/default-macor.lispになります。
if
WATのif構文は (if 条件式 (then 複数の式) (else 複数の式)) という形式ですが、Common Lisp風に (if 条件式 then式 else式) で書けるようにします。
(defmacro.wat if (test-form then-form &optional else-form) `(|if| ,test-form ,@(if else-form `((|then| ,then-form) (|else| ,else-form)) `((|then| ,then-form)))))
then式、else式に複数の式を並べたい場合は、Common Lisp と同様に progn で囲います: (if (progn 複数の式) (progn 複数の式))
when/unless
if分岐のthenの部分だけ欲しい、elseの部分だけ欲しいということは割りとあるので、Common Lisp同様に when, unless をそれぞれ用意します。先程の if の上に乗っけるだけですね。
(defmacro.wat when (test-form &body form) `(if ,test-form (progn ,@form))) (defmacro.wat unless (test-form &body form) `(if ,test-form (progn) (progn ,@form)))
cond
WATのif構文には、いわゆるelse ifにあたるものがないので、例えば分岐が3つ欲しい場合は下記のように書くことになります。
(if 条件1 then式 (if 条件2 then式 else式))
うっとうしいので、Common Lispの cond を真似て次のように書けるようにします。
(cond (条件1 複数の式) (条件2 複数の式) (t 複数の式))
実装は次の通りです。
(defmacro.wat cond (&rest clauses) (labels ((rec (rest-clauses) (unless rest-clauses (return-from rec)) (let* ((clause (car rest-clauses)) (test-form (car clause)) (form (cdr clause))) (cond ((eq test-form 't) `(progn ,@form)) ((cdr rest-clauses) `(if ,test-form (progn ,@form) ,(rec (cdr rest-clauses)))) (t `(if ,test-form (progn ,@form))))))) (rec clauses)))
少々長いですが雰囲気だけ伝われば。1点だけ、条件式部分に t が来たときはelse部分だと思って以降は無視します。
こんな感じで欲しい構文をサクサク追加していけるのはマクロがあることの利点ですね。
今後
今後...といいつつ、特にWAT書いて何かしようという展望もないのでたぶんやらないやつです。
名前空間
wat-symbol の項の注釈でチラッと触れたのですが、現状シンボルのパッケージを無視しているので、関数名などの名前空間を分けることができません。単純な実現方法としては、パース時にパッケージ名をプレフィックスにつけてしまうというのがあるかなと思います。
複数module
現状 (generate-wat-module) で全ての定義済みの関数(など)をひとまとめにして1つの大きなmoduleにします。複数のmoduleからなるものを書きたい場合はそれでは困るのでどうにかする必要があります。深くは考えていないですが、3年前(そんな前だと...)のLisp Advent Calendar記事「Parenscript上でシンボルのインポートやエクスポートを模倣する」でやったように、起点となるパッケージから依存関係を調べて1つのmoduleにまとめるような処理が必要になりそうです。
ちゃんとしたlet
記事冒頭の例ではletっぽい何かを使っていますが、wa/default-macro.lispでデフォルトのマクロとしてそれっぽく実装しただけのもので、下記の制限があるもどきに過ぎません。
- 関数冒頭にしか置くことができない
- これは中で利用しているWATのローカル変数定義の
local構文が関数冒頭にしか置けないことから来る制限です
- これは中で利用しているWATのローカル変数定義の
- (1つ目制限から自明ですが)スコープは関数全体になります
- 派生する話として、Common Lispの
letは複数の変数を定義する場合、初期化で他の変数の値を参照することができません。が、letもどきの方はそうしたスコープの分離ができていません
- 派生する話として、Common Lispの
これを解消するには下記のような修正が必要そうです。
- パース時、
localはすぐに書き出すのではなく、いったん溜めておいて一通りパースしてから関数冒頭にまとめる - 今は変数は単純に
x→$xのように固定のプレフィックスをつけるだけだが、例えば見た目のスコープに合わせてグローバルな連番をつける(x→$x-999)などできるようにする- これをやるためには、letをマクロとしてではなくスペシャルフォームとして定義する必要が出てきます
前述の名前空間、複数moduleの話に比べるとまだやっておきたい気分はあるところです。
次回
今回色々書いたような気分になりますが、実はまだ肝心のWATを1行も書いていません。ということで、次回は今回作った基盤の上で簡単なものを書いて遊んでみます。
*1:念のため、WATは改行と空白を区別しないのでWASMにコンパイルする上ではフォーマットは不要です。あくまで見易さのためです
*2:実際は関数としての定義を持たないシンボルに symbol-function を適用するとエラーを返すので判定には使えません。fboundp関数を適用した結果がtrueでかつマクロでなくかつスペシャルフォームでないもの、が正確な判定方法になるようです。さらに言うと、これはglobal environmentで定義された関数についての話で、lexical envrionmentに定義されたものはこの限りではありません
*3:現状名前空間を持たないので、割り切るならシンボルのパッケージは無視してキーワードなり文字列なりを識別子に利用するのが正しいです。が、名前空間の実装に未練があってそのままになっています...。同名で別パッケージのシンボルを入れてしまうと二重定義になるというように、実際問題があるのでよろしくないのですが...
*4:また、そもそもlexical environmentに入っているものはシンボルでないので、その点でも不正確な模倣ではあります
*5:現状ではwat-symbolのvarフィールドにtを入れているので値の有無ぐらいしか分からないのですが、ここに変換後のシンボルを返す関数を入れるようにすると、スコープもどきを実現できるのだろうな...とうっすら考えてはいます
WAT (WebAssembly Text Format) と Common Lisp で遊ぶ ~準備編~
lisp Advent Calendar 2020 7日目の記事です。
WebAssemblyを真面目に試そうと思ったらCやらRustやら他の言語からコンパイルして生成するものかと思いますが、せっかくそのテキスト形式 = WAT (WebAssembly Text Format) がS式なので直接書いて(書かせて)ちょっと遊んでみようという記事です。
2, 3回ぐらいに分けて書いていこうかと思いますが、今回は遊ぶ前の準備編で、静的なWATとそれを呼び出すJavaScriptファイルを用意して、(WATはバイナリ形式のWASMに変換した上で)配信するだけのCommon Lispサーバを作るあたりまでを扱います。
色々遊んでいるリポジトリは下記になります。
今回は下記ぐらいのコミット時点の内容になります(所々余分なコードがあるので、本文では適宜整理したものを記載しています)。
https://github.com/eshamster/try-wasm-with-cl/tree/f36397c70bfb8dd3a39d70bffb70e7370a6a87b4
また、下記あたりの記事を参考にしています。
目次
WABT (WebAssembly Binary Toolkit) のインストール
テキスト形式のWATはそのままではブラウザで解釈できないので、バイナリ形式のWASMにする必要があります。そのためのツールである wat2wasm コマンドが含まれる WABT (WebAssembly Binary Toolkit) をインストールしてパスを通します。
個人的にRoswellとEmacsを入れて開発に使っているDockerイメージ eshamster/cl-devel2 では下記のようにインストールできました。なお、素のAlpine上でも同じようにmakeできました(念のため、gitがないので apk add git は追加で必要になります)。
FROM eshamster/cl-devel2:latest
RUN git clone --recursive https://github.com/WebAssembly/wabt && \
apk add --no-cache cmake clang binutils gcc libc-dev clang-dev build-base && \
cd wabt && \
make
ENV PATH /root/wabt/bin:${PATH}
配信するファイル(など)の用意
HTML
HTMLははなから cl-markup を利用して Common Lisp で書いていますが、見れば分かるとは思うのでそのまま貼っておきます。
(html5 (:head (:title "try-wasm-with-cl") (:script :src "js/main.js" nil))
<script>タグでjs/main.jsをロードする...だけの内容です
JavaScript
JavaScript側は次のようなファイルを用意します。
/* static/js/main.js */ var importObject = { console: { log: console.log } }; WebAssembly.instantiateStreaming(fetch('wasm/main.wasm'), importObject) .then(results => { results.instance.exports.exported_func(); });
- WASM側から
console.logを呼び出せるようにimportObjectに詰めて受け渡す - WebAssembly.instantiateStreaming を利用してサーバから指定のWASMをロードする
- ロードできたらWSAM側で定義された
exported_funcを呼び出す
ちなみに、次のコミットでJavaScriptファイルは消滅して、Parenscriptと拙作ps-experiment(quiecklispリポジトリ未登録)を利用して Common Lisp コードから生成するようになりますが、本題ではないのでおいておきます。
WAT (WebAssembly Text Format)
実際に配信するのはWATではなくWASMですが、wat2wasm を呼び出してWASMにする処理はCommon Lisp側でやるので、ここではWATまで用意します。
;; static/wasm/main.wat (module (import "console" "log" (func $log (param i32))) (func (export "exported_func") i32.const 100 call $log))
- JavaScript側から渡される
console.log関数を$logという名前でimportする exported_funcという名前で関数をexport & 定義するexported_func内で$log関数に定数100を渡す- JavaScriptで
console.log(100)とするのと同じ
- JavaScriptで
ここからコンソール上でWASMを生成したい場合は wat2wasm main.wat -o main.wasm のようにすれば main.wasm が生成されます。
ちなみに、何コミットかするとリポジトリからWATファイルが消滅してCommon Lispから書き出すようになりますが、その辺りの話が次回になります。
サーバ側の用意
lack application の作成
サーバ側は、まず軽量Webアプリケーションフレームワークである ningle を利用して、ルートへのアクセス時に先程のHTMLを返すような lack application を作成します。
(defvar *app* (make-instance 'ningle:<app>)) (setf (ningle:route *app* "/" :method :GET) (lambda (params) (declare (ignore params)) (with-output-to-string (str) (let ((cl-markup:*output-stream* str)) (html5 (:head (:title "try-wasm-with-cl") (:script :src "js/main.js" nil)))))))
これに lack の lack:builder を利用して2つ程ミドルウェアをくっつけて最終的な lack application を構成します。そして、clack の clack:clackup で起動して、無事ブラウザからアクセできるようになります(下記の start-server)。
;; --- 諸々の変数 --- ;; (defvar *app* (make-instance '<app>)) (defvar *server* nil) (defvar *script-dir* (merge-pathnames "static/" (asdf:component-pathname (asdf:find-system :try-wasm-with-cl)))) (defvar *wat-path* (merge-pathnames "wasm/main.wat" *script-dir*)) (defvar *wasm-path* (merge-pathnames "wasm/main.wasm" *script-dir*)) ;; --- lack application の build & 起動する関数 --- ;; (defun start-server (&key (port 5000) (address "0.0.0.0")) (setf *server* (clack:clackup (lack:builder ;; ミドルウェア1: 本文へ (lambda (app) (lambda (env) (let ((res (funcall app env)) (path (getf env :path-info))) (when (scan "\\.wasm$" path) (wat2wasm *wat-path* *wasm-path*) (setf (getf (cadr res) :content-type) "application/wasm")) res))) ;; ミドルウェア2: ;; .js, .wasm へのアクセスは static フォルダ以下の静的ファイルを返す (:static :path (lambda (path) (when (scan "^(?:/js/|/wasm/$)" path) path)) :root *script-dir*) ;; 先程作った lack appalication *app*) :port port :address address)))
ミドルウェア2は単に静的ファイルを返すように設定しているだけです。
ミドルウェア1の方は *.wasm へのアクセスがあった場合に下記のようなことをします。
- 後述の
wat2wasmを利用してmain.watをmain.wasmにコンパイルする- 中身は
wat2wasmコマンドを呼び出しているだけです - 本来は
XXX.wasmへのアクセスならXXX.wat->XXX.wasmのコンパイルをするようにすべきでしょうが、そこは手抜きしてます
- 中身は
- HTTPヘッダの
content-typeをapplication/wasmに設定する- JavaScript側の
WebAssembly.instantiateStreamingが同content-typeを要求するためです
- JavaScript側の
WASMファイルの書き出し
ファイルが異なるので一応項を分けましたが、WAT->WASMへの変換は下記の通り wat2wasm コマンドを呼び出し、wat-path で指定されたWATファイルをWASMに変換し、wasm-path で指定されたパスにアウトプットするだけです。
(defun wat2wasm (wat-path wasm-path) (uiop:run-program (format nil "wat2wasm ~S -o ~S" (namestring wat-path) (namestring wasm-path))))
結果
ということで、下記のようにしてサーバを起動し、ブラウザから localhost:5000 にアクセスすれば、開発者コンソールに 100 が表示されるようになります。
> (ql:quickload :try-wasm-with-cl) > (try-wasm-with-cl:start-server :port 5000)
なお、最新版ではquicklispリポジトリ未登録のps-experimentに依存しています。qlfileを置いているのでqlotで取ってくるのが簡単かと思います。
> (ql:quickload :qlot) > (qlot:quickload :try-wasm-with-cl) > (try-wasm-with-cl:start-server :port 5000)
次回
Common Lisp (Parenscript) で GAS を書く
GAS (Google Apps Script) を Common Lisp (Parenscript) で書けるようにしたという話です。テンプレートを作ったのでその使い方やら中身の話やらを簡単に書いていきます。
なお、個人で実際に利用しているものとしては日報メールを生成する下記のリポジトリがあります。1年ぐらい非 Git 管理の純 JavaScript な GAS として利用していたものを、clasp で Git 管理下に置くついでに Common Lisp 化したものです。
使い方
ros template 用のテンプレートを作成したのでその使い方についてです。
なお、ros template 自体について詳細を知りたい場合は過去記事参照です。
インストール
まずはテンプレートを clone & import します。
$ git clone https://github.com/eshamster/template-cl-gas.git
$ cd template-cl-gas/src
$ ros template import
うまく行っていれば ros template checkout コマンドで次のように candiates: に cl-gas テンプレートが見えるはずです。
$ ros template checkout current default is "default" candidates: default. cl-gas
また、依存パッケージの ps-experiment が quicklisp リポジトリに登録されていない *1 のでインストールしておきます(コンソールコマンドがある訳ではないので ql:quickload できるようになれば別の方法でも良いです)。
$ ros install eshamster/ps-experiment
npm 側の準備としては @google/clasp をインストールしてログインしておくだけです。ちなみに、リモートサーバ上で開発しているような場合は clasp login --no-localhost でログインすると良いようです(参考)。
$ npm i @google/clasp -g
$ clasp login
プロジェクト作成
プロジェクト作成は次のようにします
ql:quickloadが認識できる場所に空のフォルダを作成します$ cd ~/.roswell/local-projects $ mkdir sample-cl-gasclasp createでプロジェクトを初期化します$ cd ~/.roswell/local-projects/sample-cl-gas $ clasp create sample-cl-gas --type standalone $ find . . ./.clasp.json ./appsscript.jsonros init cl-gasでcl-gasテンプレートからプロジェクトを作成します$ cd ~/.roswell/local-projects/sample-cl-gas $ ros init cl-gas sample-cl-gas \ --license LLGPL \ --description "This is a sample using template-cl-gas." $ find . . ./.clasp.json ./appsscript.json ./.gitignore ./.claspignore ./.clasp.json.in ./src ./src/main.lisp ./src/compile.lisp ./main.lisp ./compile.ros ./sample-cl-gas.asd ./README.markdown ./Makefile
トラブルシューティング
ros init 時に cl-gas テンプレートがうまく適用されずに cl-gas.ros が生成されて終わってしまう場合があります。
$ ros init cl-gas sample-cl-gas \
--license LLGPL \
--description "This is a sample using template-cl-gas."
Successfully generated: cl-gas.ros
$ ls
.
./.clasp.json
./appsscript.json
./cl-gas.ros # ← これができただけ
原因解明に至っていないですが、回避方法は以下を実行することです。これで、次に ros init を実行した際にリコンパイルが走ってひとまずテンプレートが正常に適用されるようになります。
touch /usr/local/etc/roswell/init.ros
気が向いたらきちんと調査して解決なり issue 化なりしたいですが、何しろ上記の通りリコンパイルが走った段階で直ってしまうので printf デバッグすら簡単でなく中々辛い...。
アップロード・編集
ここまでの準備をした段階で取りあえず動くものができています。 make push-new で main.js の生成と GAS へのアップロードを行います。
$ make push-new
GAS の画面から実行してみると、ログに "Hello GAS on Lisp" が表示されるはずです。

以降、ファイルを変更した場合は同様に make push-new することで反映できます。
さて、ファイルを編集する場合ですが、先程の "Hello GAS on Lisp" を出力するコードに対応するのが src/main.lisp です。
(defpackage sample-cl-gas/src/main (:use :cl :ps-experiment :parenscript) (:export :main)) (in-package :sample-cl-gas/src/main) (defun.ps main () (-logger.log "Hello GAS on Lisp"))
通常の Common Lisp 開発に近いサイクルで開発できることのデモとして、 src/hoge.lisp ファイル追加してみます。
(defpackage sample-cl-gas/src/hoge (:use :cl :ps-experiment :parenscript) (:export :hoge)) (in-package :sample-cl-gas/src/hoge) (defun.ps hoge () (-logger.log "Hello hoge on Lisp"))
そして、src/main.lisp を以下のように編集します。 :export や :import-from が通常の作法で行えることが分かるかと思います。出力される JavasScript 上でも Common Lisp のパッケージ・シンボルシステムに従った名前空間の分割をしているので、別パッケージとの名前衝突も気にする必要はありません。
(defpackage sample-cl-gas/src/main (:use :cl :ps-experiment :parenscript) (:export :main) (:import-from :sample-cl-gas/src/hoge :hoge)) (in-package :sample-cl-gas/src/main) (defun.ps+ main () (hoge))
これを make push-new して改めて実行することで、ログに "Hello hoge on Lisp" が表示されます。
付録:Parenscript + ps-experiment 上での開発概略
Parenscript + ps-experiment の開発サイクルを記事にしたことがない気がするので簡単に書くと、下記ぐらいを注意しておけば結構 Common Lisp ライクに書けるのではないでしょうか*2。先程見たようにパッケージ分割も Common Lisp の作法に則っています。
clに加えてparenscript,ps-experimentを:useするdefXXXの代わりにdefXXX.psまたはdefXXX.ps+を利用する- 用意があるのは
defvar,defparameter,defun,defmacro,defgeneric,defmethod,defstructです .psと.ps+の違いは、前者が JavaScript 用の定義のみを行うのに対し、後者は加えて同等の Common Lisp コードも定義する点です- Common Lisp コンパイラのエラー・警告という恩恵を得られるので可能な限り
.ps+を利用するのが良いです defun.ps,defgeneric.ps,defmethod.psについては空の Common Lisp コードも生成するので、 それらで定義したものを.ps+系から利用してもコンパイルエラーにはなりません(実行時エラーになります)
- Common Lisp コンパイラのエラー・警告という恩恵を得られるので可能な限り
- 用意があるのは
他、どうしても JavaScript との差異を意識しないといけない場面はあります。目立つものは下記でしょうか。
- 「ハイフン+文字」が大文字と解釈される。例:
ps-experiment→psExperiment(Parenscript の仕様)- JavaScript 側で定義されたものを呼び出す際に意識が必要な点になります
- 大文字が連続するようなケースで煩わしい場合は
(enable-ps-experiment-syntax)を利用すると#j.psExperiment#のように書けます
- 空リストと
nil(JavaScript上のnull) は同一ではない- Common Lisp 上のリストの初期化は良く
nilで行いますが(list)のようにする必要があります
- Common Lisp 上のリストの初期化は良く
- 0 が false 扱い
defvar.psなどで定義した変数はコピーが export される- そのため値の変更が反映されないという罠があります(気づかないとデバッグに結構手間がかかる...)
- 特にマクロ内で展開される変数でやりがちです
- パッケージ外に露出するものについては getter, setter を用意するのが無難です
- そのため値の変更が反映されないという罠があります(気づかないとデバッグに結構手間がかかる...)
- Parenscript 上で用意されていない Common Lisp 関数は結構ある
- ps-experiment/ps-macros-for-compatibility でマクロとして補っているものもありますが、気まぐれで追加しているので網羅性は全くないです...
実現方法
実現方法について1ファイルの Roswell スクリプトで行う方法を見てみます。テンプレートとして提供しているものは、適宜分割をしたり asd ファイルを追加してプロジェクト化したりと整えただけで、ベースの実現方法は1ファイルの場合と変わりません。
まずは少しダメな例です。
#!/bin/sh #|-*- mode:lisp -*-|# #| exec ros -Q -- $0 "$@" |# (progn ;;init forms (ros:ensure-asdf) #+quicklisp(ql:quickload '(:parenscript :ps-experiment :split-sequence) :silent t) ) (defpackage :ros.script.test.3797433527 (:use :cl :parenscript :ps-experiment)) (in-package :ros.script.test.3797433527) (defun.ps test () (-logger.log "Hello GAS on Lisp")) (defun main (&rest argv) (declare (ignorable argv)) (with-open-file (out "main.js" :direction :output :if-exists :supersede :if-does-not-exist :create) (princ (with-use-ps-pack (:this) (test)) out)))
with-use-ps-pack はパッケージ間の依存性を見つつ、export, import も適宜行いつつ JavaScript コードを文字列として出力する ps-experiment のマクロです*3。ちなみに、この辺りの細かい(細か過ぎる)話は過去に記事にしています。
さて、その with-use-ps-pack の出力を素直に princ している訳ですが何がダメかというと...
var psExperiment_defines_defmethod = (function() { /* ※ defgeneric, defmethod 実現のためのコード群なので略 */ })(); var ros_script_test_3797433527 = (function() { /* --- import symbols --- */ /* --- define objects --- */ function test() { __PS_MV_REG = []; return Logger.log('Hello GAS on Lisp'); }; function __psMainFunc__() { __PS_MV_REG = []; return test(); }; /* --- extern symbols --- */ return { '_internal': { 'test': test, '__psMainFunc__': __psMainFunc__, } }; })(); ros_script_test_3797433527._internal.__psMainFunc__();
with-use-ps-pack 内に書いた処理は __psMainFunc__ 関数として出力していますが、末尾でこれをそのまま実行してしまっています。GAS としてはこの __psMainFunc__ 関数を実行する関数が欲しいところです。
ということで、Roswell スクリプトの main 関数を下記のように変更します。
(defun main (&rest argv) (declare (ignorable argv)) (let* ((str (with-use-ps-pack (:this) (test))) (splitted (split-sequence:split-sequence #\Newline str))) (with-open-file (out "main.js" :direction :output :if-exists :supersede :if-does-not-exist :create) (format out "~{~A~%~} function main() { ~A }" (butlast splitted) (car (last splitted))))))
...末尾の一行を切り取って function main() { } で囲うという見るからに汚いことをしています。本来は with-use-ps-pack に適切なオプションをつけてどうにかできるようにすべきですが、そこまでのモチベーションが湧いていないのでひとまずこんなもので...。そんな訳で次のように無事に GAS に上げて動かせるコードが出力されました。
var psExperiment_defines_defmethod = (function() { /* ※ defgeneric, defmethod 実現のためのコード群なので略 */ })(); var ros_script_test_3797433527 = (function() { /* --- import symbols --- */ /* --- define objects --- */ function test() { __PS_MV_REG = []; return Logger.log('Hello GAS on Lisp'); }; function __psMainFunc__() { __PS_MV_REG = []; return test(); }; /* --- extern symbols --- */ return { '_internal': { 'test': test, '__psMainFunc__': __psMainFunc__, } }; })(); /* ※ここまでは上記の出力と同じ */ function main() { ros_script_test_3797433527._internal.__psMainFunc__(); }
完全に余談ですが、省略している defgeneric, defmethod の(サブセットの)実装の話は下記で記事にしています。
*1:登録したいなという気持ちはありつつ、冴えた名前が思いつかないのでそのままになっています...
*2:Common Lisp ライクに書くための皮を Parenscript に被せるのが ps-experiment の主要な役割でもあります
*3:第1引数で依存解決の起点となるパッケージ群をキーワードで指定します。ただ、依存解決を入れた時点で自身のパッケージを示すエイリアスである :this 以外を指定することがなくなってしまったので、何かオプションを追加したくなったらこちらは obsolete して別のマクロを用意しようかなという気持ちではいます
【Common Lisp】cl-base + rove + GitHub Actions でテストする
以前「cl-base + rove + Travis CI でテストする」という記事を書きましたが、その s/Travis CI/GitHub Actions/ 版です。
下記が作成したアクションのリポジトリです。
使い方
ひとまず使い方です。次の条件に合致する場合、プロジェクトに下記のような内容の .github/workflows/xxx.yml (xxx は任意) を配置するだけです。
- Docker コンテナ: eshamster/cl-base
- テストライブラリ: fukamachi/rove
- Common Lisp 処理系
- SBCL
- Clozure CL
on: [push] jobs: test: runs-on: ubuntu-latest strategy: matrix: lisp: [sbcl-bin, ccl-bin] name: A job to test Common Lisp project steps: - name: Checkout uses: actions/checkout@v2 - name: Test step id: test uses: eshamster/try-cl-test-on-gh-actions@v0.3.1 with: # 利用する処理系: 今のところ sbcl-bin or ccl-bin lisp: '${{ matrix.lisp }}' # [optional] テスト前に ros install したいものがあればカンマ区切りで指定する installTargets: 'eshamster/ps-experiment,eshamster/cl-ps-ecs'
テスト環境の /github/workspace にテスト対象のコードがあることを前提にしているので、先に actions/checkout アクションでリポジトリをチェックアウトします。
ちなみに、リポジトリ内でも動作確認していますが、(GitHub Actions 初触りなため)他プロジェクトから使えるのか不安だったので、次のリポジトリでお試し利用しています。
中身
アクションのリポジトリを再掲します。
このうち、アクションに関係するのは以下の4ファイルです。
├── action.yml
└── test-docker
├── Dockerfile
└── test.sh
Travis CI 版と比べると、docker run 部分を GitHub Actions 側でやってくれるので、test-docker/run.sh にあたるファイルがありません。
action.yml
アクション定義の本体です。
name: 'Test Common Lisp' description: 'Run test of Common Lisp project using rove on Docker' inputs: lisp: description: 'Name of Common Lisp implementation' required: true default: 'sbcl-bin' installTargets: description: 'Comma separated installation targets that can be installed by "ros install"' required: false runs: using: 'docker' image: 'test-docker/Dockerfile' args: - ${{ inputs.lisp }} - ${{ inputs.installTargets }}
特筆するところもないですが、runs.using で docker を指定することで、テストを Docker コンテナ上で走らせることを指示しています。
このアクションでは2つの引数(inputs)を取ります。
lisp: 利用する処理系の指定で今のところ下記のいずれかsbcl-binccl-bin
installTargets: [optional] テスト前に ros install したいものがあればカンマ区切りで指定する ((処理系をros useする手前でros installを実行しているので別の処理系の追加も可能ではあります。とはいえ、テスト実行のたびにインストールすることになるので Dockerfile 側を修正して追加するのが正道ですね))- 例.
'eshamster/ps-experiment,eshamster/cl-ps-ecs'
- 例.
test-docker/Dockerfile
テスト実行環境を定義する Dockerfile です。
FROM eshamster/cl-base:2.4.2
ADD ./test.sh /root
RUN ros install ccl-bin && \
ros install rove
ENTRYPOINT ["/root/test.sh"]
Travis CI 版と比べると CMD -> ENTRYPOINT になったぐらいであとは見ての通りです。Common Lisp 処理系は(デフォルトの sbcl-bin に加えて)ccl-bin を入れています。他の処理系を入れる場合はここに追加するのが良さそうです。
test-docker/test.sh
ENTRYPOINT としてコンテナ内部で起動されるスクリプトです。
#!/bin/sh set -eux lisp=$1 install_targets="${2:-}" if [ "${install_targets}" != "" ]; then echo "${install_targets}" | tr ',' '\n'| while read target; do ros install ${target} done ros -e '(ql:register-local-projects)' -q fi ros use ${lisp} # Note: Assume that repository is checkout to workspace folder in previous step dir=/root/.roswell/local-projects/target cp -R /github/workspace ${dir} # (*1) cd ${dir} rove *.asd 2>&1 | tee /tmp/test.log # Note: In Clozure CL, terminating debug console finishes in errcode 0, # so grep message to check if the test has actually run. grep "tests? passed" /tmp/test.log # (*2)
2つの引数を取ります。
- 第1引数: 利用する Common Lisp 実装
- 第2引数: 追加で
ros installするもの
下記のような微妙なハックがあります。
- (*1): 最初
ln -sでシンボリックリンクを作ろうとしていたのですが、Clozure CL ではうまく認識(ql:quickload)できなかったっため、コピーを作成しています - (*2): システムが見つからなかったなどでデバッガに入った場合即座に死んでくれる...のは良いのですが、Clozure CL ではエラーコード 0 で終了してテスト成功扱いになってしまったので、テストログを grep してテスト成功を示すメッセージがあるかを確認しています
- 追記:複数のテストが走る場合メッセージが
test passedではなくtest"s" passedになることに気付いたので v0.3.1 で修正
- 追記:複数のテストが走る場合メッセージが
参考にしたもの
今回のものをつくる上では、公式のドキュメントを見れば事足りる感じでした。基本的には「Docker コンテナのアクションを作成する」に沿っていけば良かった感じです。
設定の細かい部分に関しては適宜下記を参照しました。
- GitHub Actionsのメタデータ構文
action.ymlについてのリファレンス
- GitHub Actionsのワークフロー構文
.github/workflows/xxx.ymlについてのリファレンス
【Common Lisp】Go言語の goroutine っぽいものを作ってみたかった話
Lisp Advent Calendar 2019 23日目の記事です。
近頃仕事で書いている Go 言語の勉強も兼ねて「Go言語による並行処理」という本を買ったので Lisp を書いていくぞという内容です。goroutine っぽい cloutine なるものを Common Lisp 上で作ってみようという試みです。
できたもの(と制限)
- 隠蔽された複数の実スレッドにいわゆる Green Thread(cloutine と命名)を投げ込んで並行処理を実現する
- 非同期なチャネル
というようにできたのは一部分だけです。また、できたものについても下記の制限があります。
- 色々実用に耐えない
- SBCL 上ではさらに実用的に耐えない
- チャネルについてはかろうじて単独で動作するだけで select のような高度で実用的な機能はできていない
技術要素
次のようなものを利用して作成しました。
- マルチスレッド: bordeaux-threads
- 限定継続: cl-cont
- 簡単な使い方について「cl-cont: 限定継続」の項で簡単に解説しているので、興味のある方はそこだけ見てみると良いかもしれません
- 非同期処理: Blackbird: いわゆる Promise を実現するライブラリ
参考
- green-thread
- シングルスレッド上での Green Thread を実現するライブラリです
- 利用はしていませんが実装の参考にしています。
bordeaux-threads以外の技術要素は同じです
動かしてみる
現状 cloutine は quicklisp に登録していないので ql:quickload できるような位置にソースを持ってくることが必要です。Roswell を利用している場合は下記が簡単です。
$ ros install eshamster/cloutine
まずは次の Go のコードに相当する動作を試してみます。
package main import ( "fmt" "time" ) func main() { ch := make(chan int) // go で goroutine を1つ立てる go func() { // チャネルがクローズされるまで値を取り出して出力し続ける for { val, ok := <-ch if !ok { break } fmt.Printf("%d\n", val) } }() go func() { // 0~4までの値をチャネルに投入した後、クローズする defer close(ch) for i := 0; i < 5; i++ { ch <- i } }() // 本来 wait group でやるところをサボり time.Sleep(1) }
次のようになります。コメントに既につらみが見えています。
CL-USER> (ql:quickload :cloutine :silent t) (:CLOUTINE) CL-USER> (use-package :cloutine) T ;; goroutine ぽいもの = cloutine を実行する実スレッドを2つ立ち上げる初期化処理 CL-USER> (init-cloutine 2) #<CLOUTINE/REAL-THREADS::REAL-THREADS #x3020011BEDDD> CL-USER> (let ((chan (make-channel))) ;; clt: cloutine を作成するマクロ (clt (loop ;; チャネルに値が入ってくるのを待つ (let ((x (<-chan chan))) ;; 多値で「値, open-p」みたいに返してクローズ判定したいが、 ;; cl-cont との組み合わせがうまくいかないので苦しいクローズ判定... (when (channel-closed-value-p x) (return)) (print x)))) (clt (dotimes (i 5) ;; 値をチャネルに入れる (chan<- chan i)) ;; defer 相当のことをするために unwind-protect を利用するべきだが ;; cl-cont が対応していないので普通に close... (close-channel chan))) NIL 0 1 2 3 4
念のため、init-cloutine の引数に指定する実スレッドの数は同時に立てられる cloutine の数を制限するものではないです。次の通り、3つの実スレッドに対して5 (+1) 個の cloutine を同時に立てることができています*2。
CL-USER> (ql:quickload :cloutine :silent t) (:CLOUTINE) CL-USER> (use-package :cloutine) T ;; bt = bordeaux-threads のニックネーム CL-USER> (defparameter *lock* (bt:make-lock)) *LOCK* CL-USER> (init-cloutine 3) #<CLOUTINE/REAL-THREADS::REAL-THREADS #x3020011BECCD> CL-USER> (let ((chan (make-channel))) (dotimes (i 5) (let ((i i)) (clt (loop ;; スレッドが切り代わり易いように適当に sleep を入れて動作を乱す (sleep 0.001) (let ((x (<-chan chan))) (when (channel-closed-value-p x) (return)) (bt:with-lock-held (*lock*) ;; *real-thread-index* は実スレッドの番号 (format t "thread: ~D, cloutine: ~D, value: ~D~%" *real-thread-index* i x))))))) (clt (dotimes (i 15) (chan<- chan i) ;; 上に同じく適当に sleep を入れる (when (= (mod i 5) 0) (sleep 0.001))) (close-channel chan))) NIL thread: 2, cloutine: 1, value: 0 thread: 0, cloutine: 0, value: 1 thread: 2, cloutine: 1, value: 5 thread: 0, cloutine: 2, value: 2 thread: 2, cloutine: 1, value: 7 thread: 0, cloutine: 2, value: 8 thread: 1, cloutine: 3, value: 3 thread: 2, cloutine: 1, value: 9 thread: 0, cloutine: 2, value: 10 thread: 2, cloutine: 1, value: 11 thread: 1, cloutine: 3, value: 12 thread: 0, cloutine: 2, value: 13 thread: 2, cloutine: 1, value: 14 thread: 1, cloutine: 4, value: 4 thread: 0, cloutine: 0, value: 6
今回参考にした「Go言語による並行処理」第6章「ゴルーチンとGoランタイム」P.206 に次のような説明用のコードがあるので、同等のものを動かしてみます。
fib = func(n int) <-chan int { result := make(chan int) go func() { defer close(result) if n <= 2 { result <- 1 return } result <- <-fib(n-1) + <-fib(n-2) }() return result } fmt.Printf("fib(4) = %d", <-fib(4))
次のようになります。どうにか動作はするようです。
CL-USER> (ql:quickload :cloutine :silent t) (:CLOUTINE) CL-USER> (use-package :cloutine) T CL-USER> (defun fib (n) (let ((result (make-channel))) (clt (if (<= n 2) (chan<- result 1) (chan<- result (+ (<-chan (fib (- n 1))) (<-chan (fib (- n 2)))))) ;; 前述の通り unwind-protect を使えないので普通に close... (close-channel result)) result)) ;; warnings は見なかったことにする ;Compiler warnings : ; In an anonymous lambda form inside an anonymous lambda form inside an anonymous lambda form inside an anonymous lambda form inside an anonymous lambda form inside FIB: Undefined function FIB ; In an anonymous lambda form inside an anonymous lambda form inside FIB: Undefined function FIB FIB CL-USER> (init-cloutine 2) #<CLOUTINE/REAL-THREADS::REAL-THREADS #x302000F9D86D> ;; channel を利用するには with-call/cc で囲う必要がある(clt マクロも内部で囲っている) CL-USER> (cont:with-call/cc (print (<-chan (fib 4)))) #<PROMISE name: "attach: PROMISE" finished: NIL errored: NIL forward: NIL #x302000F9DA9D> 3
実装の基本的なアイディア
cloutine の生成と実行
goroutine っぽいもの = cloutine の裏で動作する実スレッドはそれぞれ下記のような処理を行います。この辺りは「Go言語による並行処理」第6章「ゴルーチンとGoランタイム」を参考にしています。
- 各スレッドはキューを一つずつ持つ
- 全てのキューが空のとき全てのスレッドは待ち状態になる
- いずれかのキューに関数が入っているときスレッドの待ちが解除され次の動作をする
- 自身のキューを調べ、関数が入っていればそれを実行する
- 1で取得できない場合、他のキューを順に調べて関数を見つけ次第それを実行する
したがって、cloutine を生成する clt マクロの基本的な内容は、渡された処理を lambda で包んで関数化し、上記のキューに詰め込むだけです。基本的には各スレッドは自身のキューに関数を詰めて自身で実行するのですが、「他のキューを順に調べて関数を見つけ次第それを実行する」の動作があるため、空いているスレッドは人のキュー内の関数を盗んで実行することができます。
非同期なチャネル
上記の通り、cloutine の基本的な動作だけであればそれほど面倒なところはない *3 のですが、非同期なチャネルの実装が割と厄介です。「技術要素」の項で述べた限定継続ライブラリ cl-cont と、Promise ライブラリ Blackbird はいずれもここで出てきます。
分かり易く説明できる気がしないのですが、非同期な待ちは次のように実現します(※待ちが発生しない限りはほぼ単なるスレッドセーフなキュー)。以下は取り出し待ちの例ですが、チャネルのサイズを制限した場合の投入待ちの処理もおおむね同じになります。
- チャネル操作以降の処理を「継続」= 特定の形式の関数として取り出す(cl-cont)
- Promise を作成し、解決するための関数をチャネルに保管する(Blackbird)
- 2 で作成した Promise に、解決時の処理として 1 の継続を実行する処理を登録する
- チャネルに値を投入する際に 2 で保管した関数があれば呼び出して Promise を解決する
- ここで、3で登録した継続が実行される
実装
queue: ただのキュー
https://github.com/eshamster/cloutine/blob/master/queue.lisp
特別なところはないただのキューなのでリンクだけ貼ります。head からの取り出しと tail への追加しかできない双方向リストとして実装しています。
こんな感じで利用します。
CL-USER> (use-package :cloutine/queue) T CL-USER> (defparameter *q* (make-queue)) *Q* CL-USER> (queue *q* 0) 0 CL-USER> (queue *q* 1) 1 CL-USER> (dequeue *q*) 0 CL-USER> (dequeue *q*) 1 CL-USER> (dequeue *q*) NIL
この部分は12日目の記事「【Common Lisp】REPL 上で手軽にスレッドの動作を試すためのライブラリを作った」の repl-threads と全く同じです。というより、そもそも repl-threads は cloutine を書いていて思いついたものです。ついでに言うと、6日目の記事「cl-base + rove + Travis CI でテストする」は cloutine のテストで困ったことからできたものです。
multi-queue
https://github.com/eshamster/cloutine/blob/master/multi-queue.lisp
multi-queue は次のような特徴を持つ複数のキューのまとまりです。
- 複数のキューを配列として持つ
- 全てのキューが空のとき dequeue 操作は待たされる
- いずれかのキューにデータがあるとき dequeue は次のように動作する
パッケージ定義を見ると、上記に必要な部品であるキュー・ロック・セマフォを import していることが分かります。
(defpackage cloutine/multi-queue (:use :cl) (:export :multi-queue :init-multi-queue :queue-into :dequeue-from) (:import-from :cloutine/queue :init-queue :queue :dequeue) (:import-from :bordeaux-threads :make-lock :make-semaphore :with-lock-held :wait-on-semaphore :signal-semaphore)) (in-package :cloutine/multi-queue)
クラス定義は次のようになります。複数のキューと各キューに対応する複数のロック、そして1つのセマフォを持ちます。
(defclass multi-queue () ((queues :initarg :queues :accessor mq-queues) (locks :initarg :locks :accessor mq-locks) (semaphore :initform (make-semaphore) :accessor mq-semaphore))) (defun init-multi-queue (n) (let ((queues (make-array n)) (locks (make-array n))) (dotimes (i n) (setf (aref queues i) (init-queue) (aref locks i) (make-lock))) (make-instance 'multi-queue :queues queues :locks locks)))
queue-into では指定したインデックスのキューへ値を入れ、セマフォをインクリメントします。
(defmethod queue-into ((mq multi-queue) queue-index value) (assert (< queue-index (queue-count mq))) (with-lock-held ((aref (mq-locks mq) queue-index)) (queue (aref (mq-queues mq) queue-index) value)) (signal-semaphore (mq-semaphore mq)))
dequeue-from では前述の、指定されたインデックスのキューを優先した dequeue 操作を行います。ただし、queue 操作がない限りはセマフォがインクリメントされることはないので、全てのキューが空であれば入口で待たされます。
(defmethod dequeue-from ((mq multi-queue) prior-queue-index) (assert (< prior-queue-index (queue-count mq))) ;; 全てのキューが空なら待つ (wait-on-semaphore (mq-semaphore mq)) (macrolet ((try-dequeue (index) `(with-lock-held ((aref (mq-locks mq) ,index)) (let ((value (dequeue (aref (mq-queues mq) ,index)))) (when value (return-from dequeue-from value)))))) ;; まずは指定されたインデックスのキューを調べる (try-dequeue prior-queue-index) ;; なければ別のキューを順番に見て値を取り出す (dotimes (i (queue-count mq)) (unless (= i prior-queue-index) (try-dequeue i))) ;; 上記で取れないケースはあり得ないのでエラー (error "No value is there.")))
real-threads
https://github.com/eshamster/cloutine/blob/master/real-threads.lisp
real-threads はその名の通り実スレッドです。 multi-queue を利用して各スレッドは次のように動作します。いずれの動作も multi-queue の各動作に対応しています。
- 各スレッドは
multi-queue内に対応するキューを1つずつ持つ - 全てのキューが空のとき全てのスレッドは待ち状態になる
- いずれかのキューに関数が入っているときスレッドの待ちが解除され次の動作をする
- 自身のキューを調べ、関数が入っていればそれを実行する
- 1で取得できない場合、他のキューを順に調べて関数を見つけ次第それを実行する
上記を実現するため、先程の multi-queue の他、スレッド作成・破棄の関数を import します。セマフォ関連も import していますが、これは初期化時のみの利用で、本質的な処理には絡んでいません*4。
(defpackage cloutine/real-threads (:use :cl) (:export :start-real-threads :destroy-real-threads :queue-promise) (:import-from :cloutine/multi-queue :multi-queue :init-multi-queue :queue-into :dequeue-from) (:import-from :bordeaux-threads :make-thread :destroy-thread :make-semaphore :wait-on-semaphore :signal-semaphore)) (in-package :cloutine/real-threads)
クラスの定義は次の通りです。
(defclass real-thread () ((thread :initarg :instance :accessor thread-instance) (index :initarg :index :accessor thread-index))) (defclass real-threads () ((threads :initarg :rt-array :accessor threads-array) (multi-queue :initarg :mq :accessor threads-mq) (destroied-p :initform nil :accessor threads-destroied-p)))
初期化は引数で指定されたスレッド数に応じて、multi-queue を初期化し、後述の process-thread 関数を実行する実スレッドを作成します。一応初期化が完了するまではセマフォで process-thread が走らないようにしています。
(defun start-real-threads (n) (let* ((mq (init-multi-queue n)) (rt-arr (make-array n)) (rts (make-instance 'real-threads :mq mq)) (sem-to-wait-start (make-semaphore))) (dotimes (i n) (let ((rt (make-instance 'real-thread :index i))) (setf (thread-instance rt) (make-thread (lambda () (wait-on-semaphore sem-to-wait-start) (process-thread rt rts)))) (setf (aref rt-arr i) rt))) (setf (threads-array rts) rt-arr) (signal-semaphore sem-to-wait-start :count n) rts)) ;; destroy-real-threads は略
次がその process-thread で、multi-queue から関数を取り出せたらそれを実行する、を繰り返すだけです。また、スペシャル変数 *real-thread-index* に自身のスレッド番号を束縛します。
(defvar *real-thread-index* nil) (defmethod process-thread ((rt real-thread) (rts real-threads)) (loop (let ((index (thread-index rt))) ;; dequeue-from は全てのキューが空であるうちは待たされる (let ((process (dequeue-from (threads-mq rts) index))) (assert (functionp process)) (let ((*real-thread-index* index)) (funcall process))))))
スレッドの外もしくは中からこのキューに関数を投げ込むメソッドが queue-process です。スレッド内からの場合は自身のインデックスのキューに投げます。そうでない場合は取りあえず 0 番目のキューに投げています(が乱数で選択した方が良い気もします)。
(defmethod queue-process ((rts real-threads) (process function)) (when (threads-destroied-p rts) (error "The thread has been destroied.")) (queue-into (threads-mq rts) (if *real-thread-index* *real-thread-index* 0) process))
cloutine
https://github.com/eshamster/cloutine/blob/master/cloutine.lisp
本題の cloutine の実装ですが、処理の実体は real-threads が担っているので、ほぼそのラッパー程度の役割です。次のように real-threads の他に、後のチャネルの実装の仕込みとして cl-cont のシンボルをいくつか import します。
(defpackage :cloutine/cloutine (:use :cl) (:export :init-cloutine :destroy-cloutine :cloutine :clt) (:import-from :cloutine/real-threads :start-real-threads :destroy-real-threads :queue-process) (:import-from :cl-cont :with-call/cc :without-call/cc)) (in-package :cloutine/cloutine)
初期化関数は次の通りで、グローバルに real-threads を1つ作成します。
(defvar *real-threads* nil) (defun init-cloutine (n) (setf *real-threads* (start-real-threads n))) ;; ※destroy-cloutine は省略
cloutine を作成する cloutine マクロとそのエイリアスの clt マクロは次のようになります。ほぼ body 部を lambda で包んで real-threads の queue-process に渡すだけです。with-call/cc, without-call/cc については次のチャネルの項を参照してください。
(defmacro cloutine (&body body) `(queue-process *real-threads* (without-call/cc (lambda () (with-call/cc ,@body))))) (defmacro clt (&body body) `(cloutine ,@body))
channel
チャネルの実装の前に、限定継続ライブラリ cl-cont と Promise ライブラリ Blackbird について簡単に見ていきます。
cl-cont: 限定継続
限定継続についてざっくり感覚的な理解を得るには κeen さんの Common Lispで限定継続と遊ぶ などを見ながら cl-cont をいじってみるのが良いのかなと思います。自身も継続を使ってみるのは始めてでざっくりとした理解しかありませんが...。
ここでは継続とは何かという話は置いて、どの様な動きをするのかいくつかの例で見てみます。まずは単純に継続 = 「以降の処理」を取り出す様子を見てみます。
;; ※ややこしいので以降 print の出力のみ記載し、REPLの出力は省略します CL-USER> (defparameter *cont* nil) CL-USER> (cont:with-call/cc (print :start) ;; let/cc 以降の処理 = 継続が k に束縛される (cont:let/cc k (print :let-start) (setf *cont* k) (print :let-end)) ;; ↓はまだ処理されない (print :end)) :START :LET-START :LET-END ;; 継続は関数として表されるので funcall できる CL-USER> (funcall *cont*) :END ;; もちろん何度でも呼べる CL-USER> (funcall *cont*) :END
この with-call/cc で defun を囲ったものが defun/cc で、次のように使えます。始めて試してみたときは、うわ本当に関数外の処理(継続)を引き込んで好きに扱える!と中々シビれました。
CL-USER> (defparameter *cont* nil) CL-USER> (cont:defun/cc test-cc () (cont:let/cc k (setf *cont* k))) CL-USER> (cont:with-call/cc (print :start) (test-cc) (print :end)) :START CL-USER> (funcall *cont*) :END
さて、限定継続として取り出される関数は0個または1個の引数を取ります。ここまでは0引数の例でしたが、チャネルからの値の取り出し待ちをする継続は値を待っているので、そこに引数として渡してあげる必要があります。次のようにチャネルにまだ値がなかった場合の値取り出しの動作を模してみます。
CL-USER> (defparameter *cont* nil) CL-USER> (cont:defun/cc like-waiting-chan () (cont:let/cc k (setf *cont* k))) CL-USER> (cont:with-call/cc (print :start) ;; まだチャネルに値が入っていないので残りの処理はどこか(*cont*)に格納しておいて ;; いったん処理は完了させる...という体 (print (like-waiting-chan)) (print :end)) :START ;; どこからかチャネルに値 100 が供給された...という体 CL-USER> (funcall *cont* 100) 100 :END
最後に実装時の細かい部分になりますが、 without-call/cc に触れます。ここまでに見たように、単純に with-call/cc を利用すると、 let/cc 以降の処理が全て束縛されてしまいます。実際にはもう少し範囲を絞りたいのですが、そのときの区切りとして利用するのが without-call/cc です。次のように使います。
CL-USER> (cont:with-call/cc (print :outer-start) (cont:without-call/cc (cont:with-call/cc (print :start) (cont:let/cc k (setf *cont* k)) ;; ここはまだ待って欲しい (print :end))) ;; ここはすぐ処理されて欲しい (print :outer-end)) :OUTER-START :START :OUTER-END CL-USER> (funcall *cont*) :END
Blackbird: Promise
Blackbird はいわゆる Promise(Future とも)を実現するライブラリで、非同期処理を実現するための部品として利用できます。次は resolve 済みの Promise を生成するだけの余り意味のない例です。
CL-USER> (ql:quickload :blackbird :silent t) (:BLACKBIRD) ;; bb = blackbird CL-USER> (let ((promise (bb:with-promise (resolve reject) (resolve 100)))) ;; promise が resolve されない限り attach された関数は実行されない ;; 今回は resolve 済みなのですぐ実行される (bb:attach promise (lambda (x) (format t "~&resolved: ~D~%" x)))) resolved: 100 ;; ↓式自体は promise クラスを返している #<PROMISE name: "attach: PROMISE" finished: T errored: NIL forward: NIL #x302000E6E2FD>
実際に非同期処理の文脈で利用するには大きく2つの方法があります。
- cl-async のような非同期処理と組み合わせる
- cl-async は libuv ベースの非同期処理ライブラリです
- Blackbird 冒頭の例で紹介されている方法です
- Promise 生成時に resolve 処理を外に保管しておいて後から resolve してもらう
今回とるのは後者の方法です。ここで、with-promise の resolve(と reject)は macrolet として定義されているため、そのまま外に渡すことはできません。こうした用途のためにはキーワード引数の resolve-fn(reject-fn)が用意されているので、そちらを外に渡します。
CL-USER> (let* (resolver (promise (bb:with-promise (resolve reject :resolve-fn resolve-fn) ;; resolve-fn を外に渡す (setf resolver resolve-fn)))) ;; promise が resolve されていないのですぐには実行されない ;; 名前の通り、resolve 時にやって欲しい処理を promise に atttach するだけ (bb:attach promise (lambda (x) (format t "~&resolved: ~D~%" x))) (print :after-attach) ;; ここで promise が resolve されるので上記の lambda も実行れる (funcall resolver 999) (print :after-resolve)) :AFTER-ATTACH resolved: 999 :AFTER-RESOLVE :AFTER-RESOLVE ; ← ※REPL の出力
これと cl-cont と組み合わせることでチャネルの待ちを実現できそうです。
- チャネルに値が入っていないときは、
resolve-fnを保管して Promise を生成し、残りの処理 = 継続を attach しておく - チャネルに値を入れる際に保管された
resolve-fnに値を渡して attach された継続を実行する
実装
https://github.com/eshamster/cloutine/blob/master/sync/channel.lisp
問題の実装を見ていきます。パッケージ定義は以下の通りで、ここまでに説明した cl-cont, Blackbird を import しています。また、値を入れる容器として queue を、その排他制御のためにロック関連のシンボルを import しています。
(defpackage cloutine/sync/channel (:use :cl) (:export :make-channel :close-channel :<-chan :chan<- :ch-closed-p) (:import-from :cloutine/cloutine :clt) (:import-from :cloutine/queue :init-queue :queue :dequeue :queue-length) (:import-from :blackbird :attach :with-promise) (:import-from :bordeaux-threads :make-lock :acquire-lock :release-lock :with-lock-held) (:import-from :cl-cont :defun/cc :let/cc)) (in-package :cloutine/sync/channel)
クラス定義は次の通りです。3つのキューを持っているところが特徴的です。
queue: チャネルに投入されるデータを管理するキュー- 以降の説明で単に「キュー」と言った場合はこのキューのこと
queue-resolver-queue: 投入待ち(キューが一杯のとき)を表す Promise の resolver (resolve-fn) を管理するキューmax-lengthが nil の場合は利用されない
deqeueue-resolver-queue: 受け取り待ち(キューが空のとき)を表す Promise の resolver (resolve-fn) を管理するキュー
(defclass channel () ((queue :initform (init-queue) :reader ch-queue) (queue-resolver-queue :initform (init-queue) :reader ch-queue-resolvers) (deqeueue-resolver-queue :initform (init-queue) :reader ch-dequeue-resolvers) (lock :initform (make-lock "Channel lock") :accessor ch-lock) (max-length :initarg :max-resource :reader ch-max-resource) ; param (closed-p :initform nil :accessor ch-closed-p))) (defun make-channel (&optional max-resource) (make-instance 'channel :max-resource max-resource))
チャネルから値を取り出す関数 <-chan の実装は次のようになります。解説はソース中にコメントしていますが、色々とつらみが見え隠れします。
(defmacro with-release-lock ((lock) &body body) `(unwind-protect (progn ,@body) (release-lock ,lock))) (defun/cc <-chan (ch) (let ((lock (ch-lock ch)) (q (ch-queue ch))) ;; let/cc が unwind-protect に囲われてしまうとうまく動作しないので、 ;; (内部に unwind-protect を含む)with-lock-held マクロは利用できない (acquire-lock lock) (cond ;; キューに値が入っているケース ((> (queue-length q) 0) (with-release-lock (lock) ;; 投入待ちがあれば resolve しておく ;; (一瞬 max-length を越えるがロック内で解消するのでまあ良いのでは...) (when (> (queue-length (ch-queue-resolvers ch)) 0) (funcall (dequeue (ch-queue-resolvers ch)) t)) (dequeue q))) ;; ここから下はキューが空のケース ;; チャネルがクローズ済みなら待たずに終わる ((ch-closed-p ch) (with-release-lock (lock) (make-instance 'channel-closed-value))) ;; まだチャネルが開いていれば待つ (t (let ((promise (with-promise (resolve reject :resolve-fn resolver) ;; 取り出し待ち解決のための resolver を溜めておく (queue (ch-dequeue-resolvers ch) resolver)))) (release-lock lock) (let/cc k ;; 値取り出し後の処理を Promise に attach しておく (attach promise (lambda (val closed-p) ;; closed-p をもらっているが、継続に多値をうまく渡す手段がなく ;; 使えないままになっている... (declare (ignore closed-p)) ;; 値を渡して新しい cloutine 上で継続を実行する (clt (funcall k val))))))))))
チャネルへ値を投入する関数 <-chan の実装は次のようになります。こちらも色々つらい。
(defun/cc chan<- (ch value) (let ((lock (ch-lock ch)) (q (ch-queue ch)) (max-length (ch-max-resource ch))) ;; 上に同じく with-lock-held を使わずに頑張る (acquire-lock lock) (cond ((ch-closed-p ch) ; チャネルがクローズ済み (with-release-lock (lock) ;; 一応 error を返しているが、継続内ではうまく拾えない... (error "Error: Insert a value into a closed channel"))) ;; 取り出し待ちがある場合 ((> (queue-length (ch-dequeue-resolvers ch)) 0) (let (resolver) (with-release-lock (lock) (setf resolver (dequeue (ch-dequeue-resolvers ch)))) ;; キューを介さずに直接値を渡す (funcall resolver value t))) ;; キューに空きがある = 投入可能な場合 ((or (null max-length) (< (queue-length q) max-length)) (with-release-lock (lock) (queue q value))) ;; キューに空きがない場合 (t (let ((promise (with-promise (resolve reject :resolve-fn resolver) ;; 投入待ち解決のための resolver を溜めておく (queue (ch-queue-resolvers ch) resolver)))) (release-lock lock) (let/cc k ;; 値投入とその後の処理を Promise に attach しておく (attach promise (lambda (open-p) (if open-p (progn ;; キューに値を入れる ;; (ロックは resolver を呼び出した側でかけている) (queue q value) ;; 新しい cloutine 上で継続を実行する (clt (funcall k))) (error "Error: Channel is closed when waiting to insert a value"))))))))))
最後に close-channel の実装も示します。残っている resolver を呼び出して全ての待ちを解決済みにします。
(defmethod close-channel ((ch channel)) "Close channel and broadcast signal to all waiting readers and writers." (let ((lock (ch-lock ch))) (with-lock-held (lock) (setf (ch-closed-p ch) t) (dotimes (i (queue-length (ch-queue-resolvers ch))) (funcall (dequeue (ch-queue-resolvers ch)) nil)) (dotimes (i (queue-length (ch-dequeue-resolvers ch))) (funcall (dequeue (ch-dequeue-resolvers ch)) nil nil)))))
*1:CCL上ではロックが recursive-lock として実装されているようで、少々雑にロック・アンロックをしても通ってしまうので、SBCL で検査しているといった理由もあります(なお、逆に SBCL には recursive-lock の実装がなさそう)
*2:同じ cloutine が必ず同じスレッドで実行されているのは意図通りではないので何かバグがあるかも...
*3:実際の goroutine のランタイムはもっと賢いことをしているはずですが
*4:抜き出した範囲では利用していないので抜いていますが、ロック関連も import しています。ただし、それらもデバッグ機能作成用であって、同じく本質的な処理には絡んでいません